Peu de temps pour une pause avec ZGC

Clément de Tastes
Tech Lead

Peu de temps pour une pause avec ZGC
ZGC est le dernier né de la famille des Garbage Collectors que propose la JVM HotSpot.
A ce jour, il revendique :
-
Des temps de pause maximums inférieurs à la milliseconde, indépendamment de la taille de la heap memory
-
Une scalabilité allant de 8 Mo à 16 To de heap
-
Une mise en œuvre facilitée par le peu de configuration nécessaire
Naissance et ambitions
La JEP 333 (JDK Enhancement Proposal) fixe ses premières ambitions. Il est alors question d’un objectif de temps de pause sous les 10ms, d’une dégradation du throughput inférieure à 15% par rapport à G1GC (devenu le GC par défaut depuis Java 9) et d’un support limité à Linux. Il n’a pas vocation à supplanter G1, mais d’offrir une réponse aux besoins de très faible latence.
Le JDK 11 propose une première mouture expérimentale qui posera les fondations pour les évolutions futures.
Par simplification, on peut mesurer la performance d’un GC selon 3 principaux axes :
| Axe | Description |
|---|---|
| CPU “Throughput” | Disponibilité du temps CPU à l’exécution de l’application en elle-même, par opposition au temps passé au fonctionnement du GC |
| Empreinte mémoire | Empreinte / coût mémoire |
| Latence | Temps de pause liés à l’activité du GC |
Même si les évolutions constantes de la JVM ont permis des améliorations conjointes sur ces axes pour tous les GC au fil du temps, le fait de privilégier l’un se fait généralement au détriment des autres.
Le choix d’un algorithme plutôt qu’un autre relève donc de l’axe de performance que l’on souhaite privilégier.
Vous l’aurez compris, ZGC met la priorité à la minimisation des temps de pause.
Ces temps de pause ont une complexité en O(1), autrement dit, en temps constant. Elles n’augmentent pas proportionnellement à la quantité de données à collecter.
Comme tout vient avec un coût, il est attendu que l’on observe une dégradation des autres axes, notamment du throughput. Les différents travaux et évolutions devront tâcher d’en diminuer l’impact.
A titre d’exemple, un récapitulatif des axes mis en avant par certains GC :
| GC | Optimisé pour |
|---|---|
| Serial | Mémoire |
| Parallel | CPU |
| G1 | Equilibre CPU / Latence |
| CMS (deprecated) | Latence |
| Shenandoah | Latence |
| ZGC | Latence |
Arrivée à maturité
La stratégie de releases régulières du JDK mettant à disposition des features expérimentales a pu porter ses fruits. La livraison d’une fonctionnalité de cette complexité a pu se faire graduellement, par l’ajout continu d’améliorations, de corrections de bugs et de prise en compte des feedbacks de la communauté.
Ce processus lui permet ainsi d’atteindre le stade de « Production Ready » dans le JDK 15 au travers de la JEP 377. Oracle considère qu’il a désormais la maturité suffisante pour quitter son statut expérimental et cela pour plusieurs raisons :
-
de nombreuses améliorations et corrections de bugs ont été implémentées
-
les performances enregistrées sont satisfaisantes
-
les feedbacks de la communauté sont positifs
-
la compatibilité avec les plateformes habituelles est assurée (Linux, Windows, macOS)
-
il n’y a plus de bug ouvert sur ZGC depuis plusieurs mois
Le travail ne s’arrête pas là pour autant et les releases suivantes apportent elles aussi leur lot d’améliorations.
Livrée dans le JDK 16 la JEP 376 “Concurrent Thread-Stack Processing” est une évolution majeure qui vient réduire considérablement les temps de pause en franchissant le seuil de la milliseconde, et ce sans concession sur le throughput.
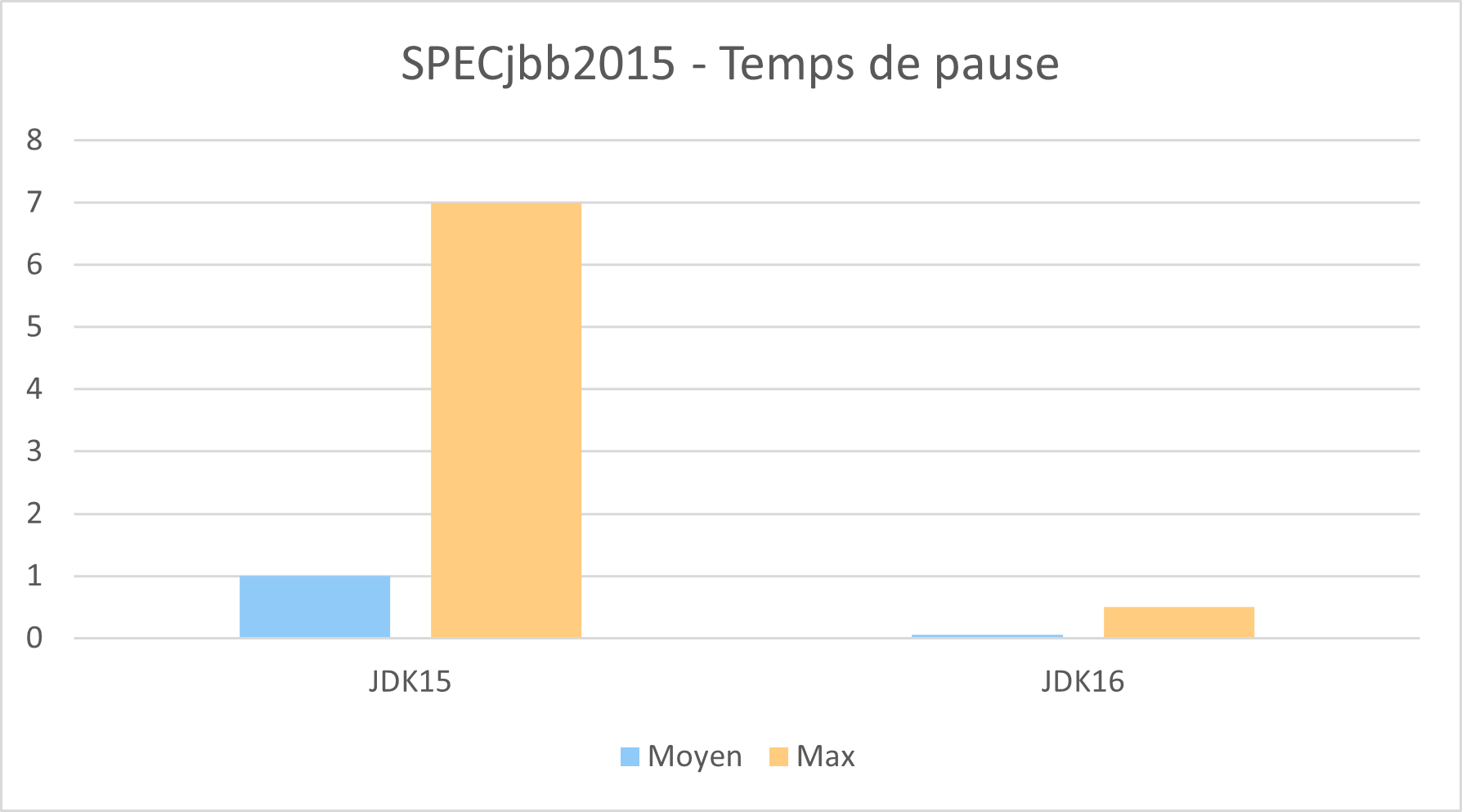 3To Heap / 224 Hyper-threads (Intel) / ~2100 Threads Java - Source: Oracle
3To Heap / 224 Hyper-threads (Intel) / ~2100 Threads Java - Source: Oracle
Quelques principes de fonctionnement
Cycle de vie
Le cycle de fonctionnement de ZGC comporte 3 phases. Chacune débute par un point de synchronisation “safepoint” impliquant une pause de tous les threads applicatifs, alias STW “Stop-The-World”. En dehors de ces 3 points l’intégralité des opérations est réalisée de façon concurrente au reste de l’application. Ces pauses sont toujours inférieures à la milliseconde.
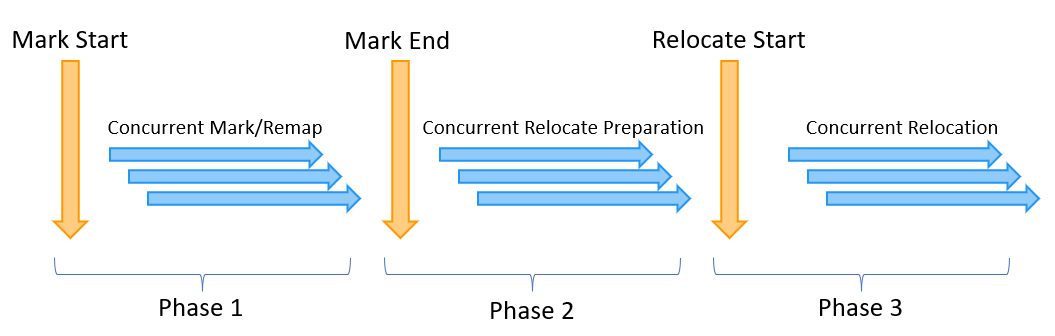
Phase 1
Le cycle débute par une pause de synchronisation (STW1) qui permet :
-
aux threads de déterminer la bonne “couleur” à utiliser (cf. Colored Pointers)
-
de créer les pages mémoire (cf. ZPages)
-
de s’assurer que toutes les “GC roots” sont valides (ont la bonne couleur), en les corrigeant si nécessaire (cf. Load Barriers)
La phase concurrente de Marking / Remapping qui s’ensuit est la traversée du graphe d’objets pour marquer les objets candidats à la collecte.
Phase 2
La pause STW2 permet de clôturer la phase de marquage.
Les traitements concurrents quant à eux permettent de déterminer quelles régions de la mémoire devront être compactées.
Phase 3
Après la détermination - à nouveau - de la bonne couleur en vigueur en STW3, les objets sont déplacés de manière concurrente pour compacter la mémoire, ce qui achève le cycle.
ZPages
ZGC subdivise la heap memory en régions (petites, moyennes et grandes) appelées ZPages. En fonction de sa taille, un objet est alloué dans une page d’une certaine taille. Les pages de petites et moyennes tailles peuvent accueillir plusieurs objets tandis que les grandes n’en acceptent qu’un seul. Ceci afin d’éviter de déplacer les grands objets, ce qui impliquerait la copie d’une large plage mémoire et pourrait provoquer des excès de latence.
Les pages sont allouées au début du cycle (STW 1) et accueilleront les objets créés au cours de ce même cycle. Ces pages fraîchement créées sont exemptées de collecte pour ce cycle. Ainsi, seules les pages antérieures au cycle en cours sont collectées.
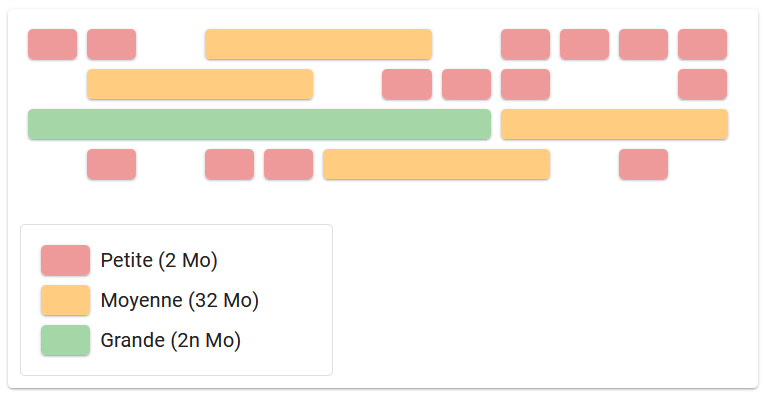
Compactage
Les objets de la heap sont constamment “compactés” afin de résoudre le phénomène de fragmentation progressive de la mémoire et garantir la rapidité dans l’allocation de nouveaux objets.
Au cours du cycle de vie, les pages candidates au compatactage sont marquées en phase 2 (généralement celles contenant le moins d’objets), puis tous les objets qui y résident relocalisés en phase 3. Lorsqu’une page est vide de tout objet, la mémoire peut être récupérée.
Afin de réaliser ces opérations de relocation de façon concurrente, ZGC maintient des tables de routage. Celles-ci sont stockées off-heap et optimisées pour une lecture rapide, au détriment d’un surcoût mémoire.
Colored Pointers
Le principe consiste à stocker de l’information relative au cycle de vie d’un objet au sein même de son pointeur. C’est un élément clé qui autorise la réalisation de nombreuses opérations de manière concurrente.

4 bits sont dédiés au stockage des méta-données et 44 bits restent adressables (on retrouve les 16 To promis), le reste étant inutilisé.
Le multi-mapping de mémoire permet à plusieurs adresses virtuelles de pointer sur la même adresse physique. Deux pointeurs dont l’adresse virtuelle ne diffère que par leur méta-données pointent sur la même adresse physique.
La “couleur” d’un pointeur est déterminée par l’état des 3 meta-bits Marked0 (M0), Marked1 (M1) et Remapped (R), et seul l’un de ces trois bits peut valoir 1.
Une couleur est soit bonne, soit mauvaise, et cela est déterminé de façon globale à plusieurs étapes du cycle de vie.
On obtient donc 3 couleurs : M0 (100), M1 (010) et R (001).
Les objets nouvellement instanciés sont marqués de la bonne couleur.
M0 et M1 sont utilisés pour tagger les objets à collecter. Le cycle de ZGC démarre par une courte pause (STW 1) dans laquelle la bonne couleur est déterminée en faisant alterner successivement les valeurs des bits M0 et M1. Ainsi, si M0 est la bonne couleur, ce sera M1 au prochain cycle.
Durant la phase concurrente suivante (Concurrent Mark/Remap), si le GC rencontre un pointeur avec une mauvaise couleur, il sera mis à jour vers la bonne adresse et estampillé de la bonne couleur.
Remapped indique que la référence a été relocalisée. Dans le dernier point de synchronisation du cycle (STW 3) R devient la bonne couleur.
Load Barriers
ZGC se démarque des autres algorithmes en ayant recours aux “load barriers” plutôt qu’aux “write barriers”. Ceci facilite la relocalisation des objets de façon concurrente. Ainsi, un objet peut être déplacé à tout moment sans que les pointeurs le référençant ne soient mis à jour. Les “load barriers” interceptent la lecture de ses pointeurs et les corrigent.
Le principe est l’insertion de code interceptant la lecture d’un pointeur. Ce code est ajouté à la volée par le compilateur JIT (Just In Time) et est capable de lire la couleur du pointeur. Les deux mécanismes fonctionnent donc de paire.
En fonction des valeurs des méta-données et de l’étape actuelle du cycle de vie, une correction du pointeur peut être effectuée. Par exemple, s’il pointe vers un objet ayant été relocalisé, ce code corrigera le pointeur.
Ce mécanisme permet de s’assurer qu’à tout moment, lorsqu’un pointeur est chargé il pointe vers le bon objet alors que les threads du GC et de l’application tournent de manière concurrente.
Mise en oeuvre
Voici l’option pour activer ZGC :
-XX:+UseZGC
La liste complète des options disponibles est consultable sur le Wiki OpenJDK.
Tuning
Une des promesses de ZGC est sa facilité de mise en oeuvre.
Il peut sereinement être utilisé “out of the box”.
On ne retiendra qu’un paramètre : -Xmx pour spécifier la valeur maximale de heap memory de la JVM.
Globalement, plus la valeur est élevée, mieux c’est. Pour autant, il y a un compromis à trouver pour ne pas monopoliser inutilement de la mémoire.
Benchmarks
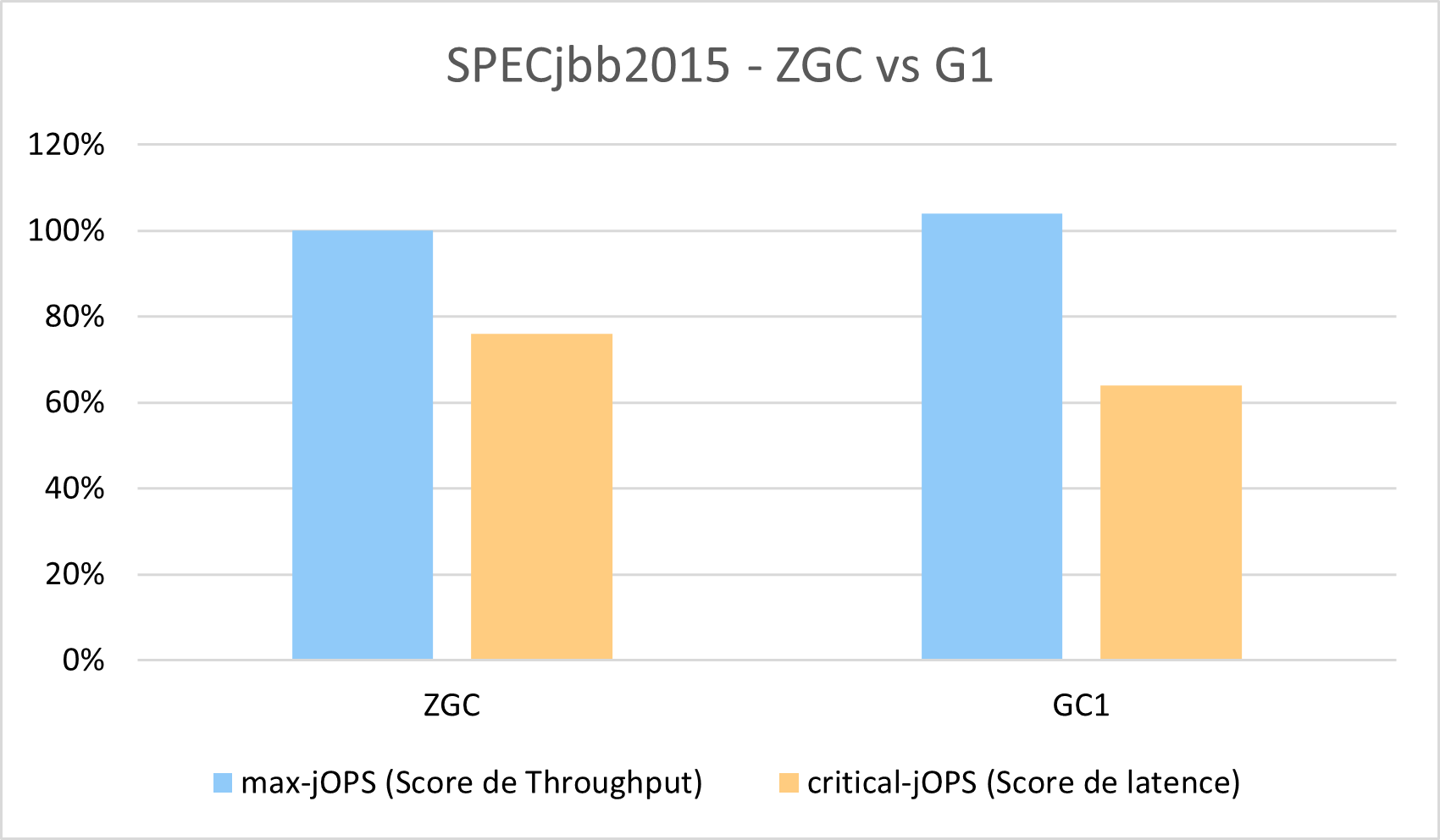
Ces résultats (source Oracle) utilisent le benchmark SPECjbb2015.
Ici l’on compare ZGC, notre sujet, et le GC par défaut de la JVM server à savoir G1.
max-jOPS est une mesure du throughput et critical-jOPS de la latence.
C’est un score : plus la valeur est élevée et meilleure est la performance.
 Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
Peu de surprise, on constate de meilleures performances en termes de throughput sur G1 mais un meilleur score de latence pour ZGC.
Comparaison des temps de pauses moyens et maximum, ainsi que quelques centiles de la distribution statistique.
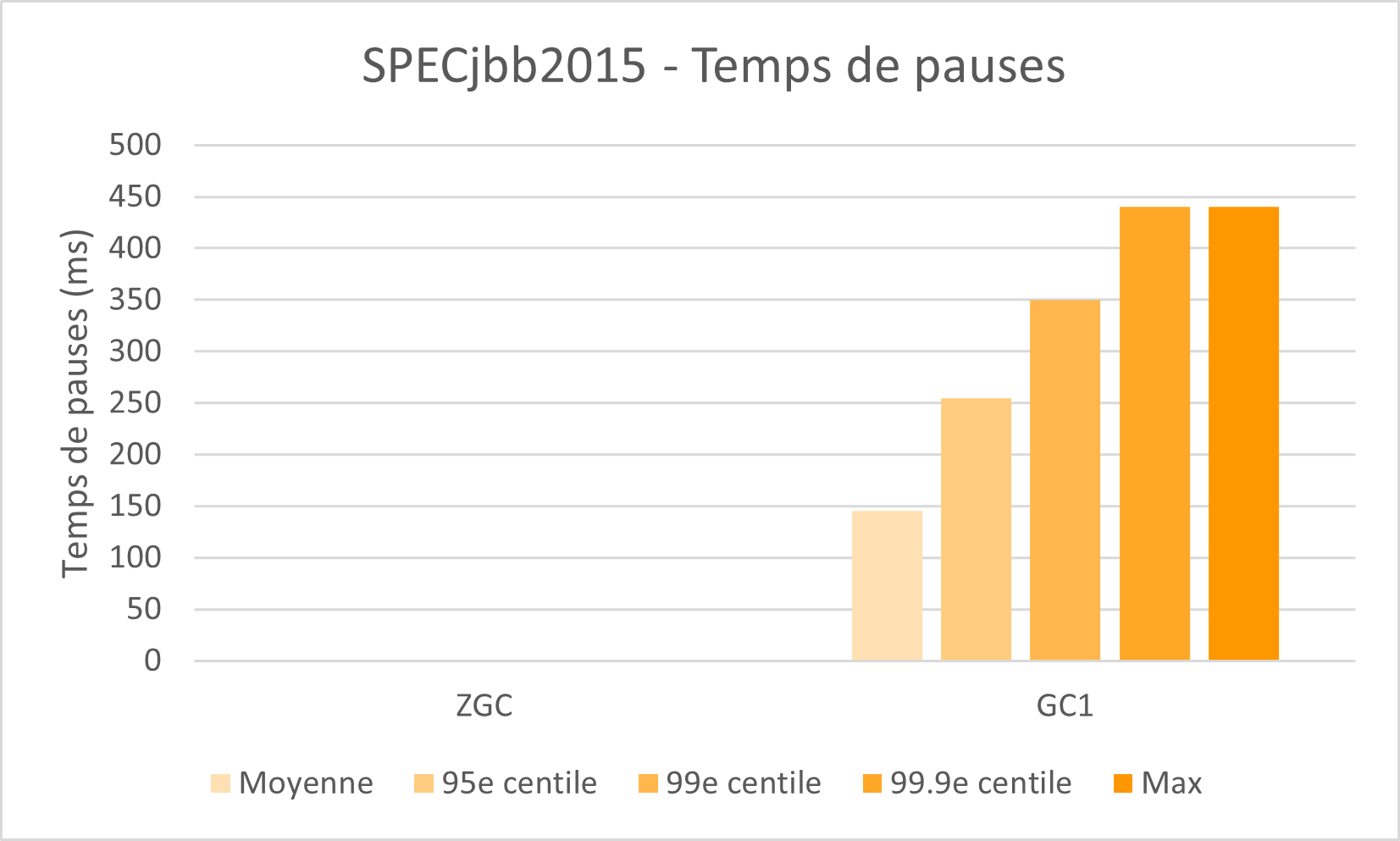 Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
Contrairement à ce que donne à penser ce graphique, les valeurs de ZGC n’ont pas été supprimées mais sont tellement faibles qu’elles ne sont pas représentables à cette échelle.
Même benchmark que le précédent, si ce n’est que l’on zoom par un facteur 1000, passant de la milliseconde à la microseconde.
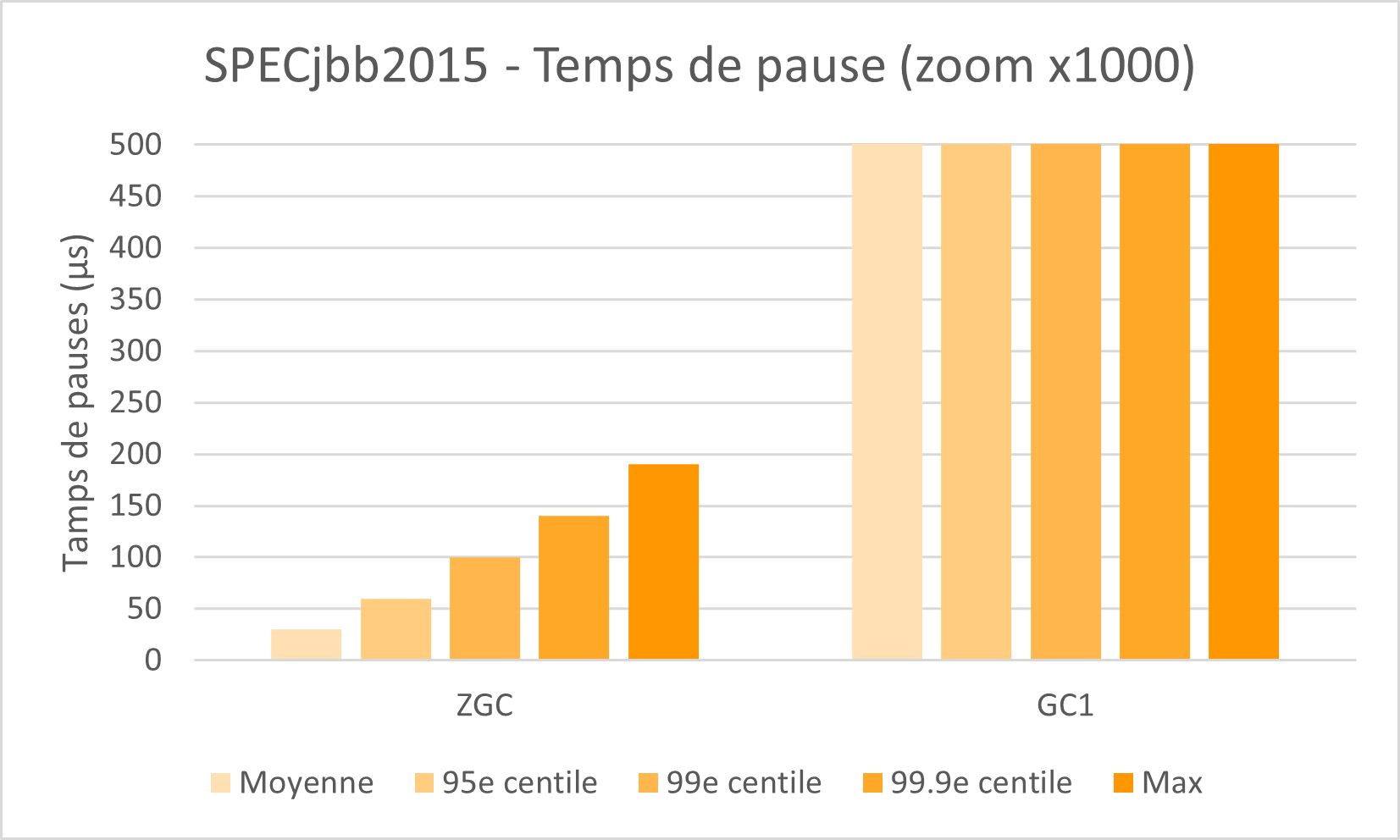 Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
A cette échelle on visualise les temps de pause, tous largement sous la milliseconde.
Comparaison des performances de ZGC sur les releases 15, 16 et 17 du JDK.
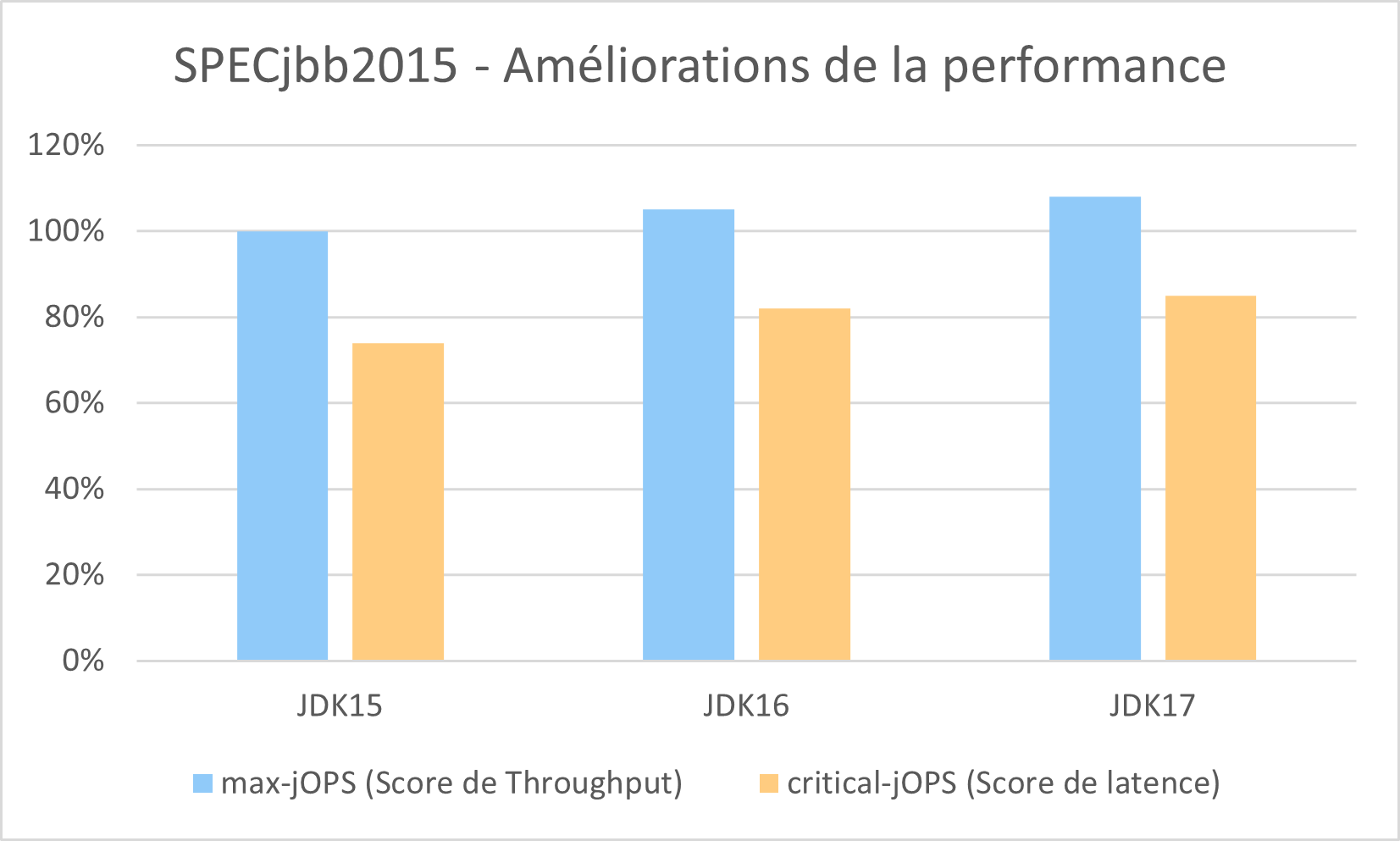 Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
Heap 128G / 40 Hyper-threads (Intel) - Source: Oracle
On constate des améliorations constantes des performances de l’algorithme.
Vers un algorithme générationnel
ZGC n’utilise actuellement qu’une seule génération. Ce fonctionnement, s’il présente des facilités de mise en oeuvre, l’oblige à parcourir tous les objets lors de la collecte. Ceci prend un temps proportionnel au nombre d’objets en mémoire et peut être prohibitif pour les grandes applications.
Une approche empirique montre que les “jeunes” objets ne survivent qu’une courte période de temps. La répartition des objets par génération - stratégie nullement spécifique à ZGC - est un axe majeur d’amélioration de ses performances. Cette séparation permet une collecte indépendante de la “young generation” et des gains considérables pour le CPU.
Les travaux en ce sens sont en cours. La roadmap est spécifiée par JDK-8272979 et une version Early-Access basée sur JDK 21 est mise à disposition par Oracle.
Encore une fois, la simplicité de configuration est mise en avant. On pourra oublier les options -Xmn (taille de jeune génération), -XX:TenuringThreshold (seuil pour passer dans la génération supérieure), ainsi que -XX:ConcGCThreads car tout est fait dynamiquement au runtime.
Les benchmarks préliminaires montrent des résultats très encourageants.
Sur SPECjbb2005, la quantité de mémoire à allouer pour maintenir un fonctionnement nominal à très faible latence diminue de l’ordre de 60%. Quand il fallait 15 Go de mémoire pour le ZGC non-générationnel, il n’en faudra que 6 avec le ZGC générationnel. Et dans le même temps, on obtient un gain de throughput substantiel grâce aux économies réalisées sur la collecte des jeunes générations.
Sur Apache Cassandra, on note des gains encore plus spectaculaires allant jusqu’à un facteur 4 pour le throughput et cela pour le coût d’un quart de la mémoire.
Le mot de la fin
Arrivé dans le JDK 11, ZGC expérimental était déjà un tour de force.
Depuis, les évolutions ont été nombreuses et les gains associés tout à fait notables. Les perspectives à venir sont tout autant voire plus réjouissantes. Avec toujours, quasiment aucun tuning requis pour bénéficier de toutes les promesses de ZGC.
Par curiosité…
Un GC sans la moindre pause, ça existe ?
Oui. La JVM propriétaire d’Azul Prime (anciennement Zing) embarque le C4 Garbage Collector (pour Continuously Concurrent Compacting Collector). Il présente un grand nombre de similarités conceptuelles (cycle de vie, load barriers, pages, générations…) mais ne fonctionne que sur un OS Linux customisé par Azul. Et il faudra mettre la main au portefeuille et sortir du monde de l’open-source pour espérer en profiter. Il n’est pas certain que cela en vaille la chandelle.
On peut également citer un candidat hors catégorie, Epsilon GC, qui n’a pas de pause… car il ne collecte pas.
Au fait, le “Z” de ZGC, il signifie quoi ?
Et bien… rien. C’est juste un nom. Décevant non ?
Il tire son inspiration sous forme d’hommage du système de fichier ZFS, révolutionnaire en son temps.
Acronyme pour lequel le Z signifiait originellement “zettabyte” mais qui fut abandonné pour ne plus rien signifier en fin de compte.
Sommaire :