Architecture Hexagonale par la pratique : partie 1

Ricken Bazolo
Référent technique
Publié le 27/10/2023
•Temps de lecture : 8 minutes

Architecture Hexagonale par la pratique : partie 1
Pour cette première partie, nous allons parler des éléments de l’architecture hexagonale : entités du domaine, cas d’utilisation, ports et adaptateurs. Nous allons appliquer ces principes à notre projet pour avancer progressivement en apprenant comment organiser notre code.
Architecture hexagonale
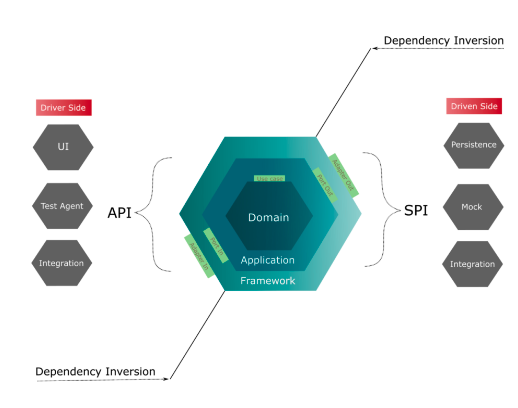
Introduit par Alistair Cockburn, ce pattern d’architecture aussi connu sous le nom de Port & Adapters Architecture place le métier au centre de l’architecture. L’une des principales idées de cette approche architecturale est d’isoler la logique métier des services techniques d’une application. Ce principe peut être mis en relation avec le Domain-Driven Design (DDD). Ces deux concepts peuvent être complémentaires. Dans cet article nous n’allons pas traiter les aspects du DDD.
| Il est également essentiel de garantir que l’aspect technologique dépende de l’aspect métier, permettant ainsi à ce dernier d’évoluer sans être entravé par la technologie employée pour atteindre les objectifs du métier. |
Les éléments de l’architecture hexagonale
En partant de la nécessité d’isoler la logique métier des services techniques d’une application, nous devons trouver un endroit pour placer le code métier afin qu’il soit isolé et protégé de tout souci technologique. Cela donnera lieu à la création de notre premier hexagone : l’hexagone du Domaine.
Nous avons également besoin de moyens pour utiliser, traiter et orchestrer les règles métier provenant de l’hexagone de domaine. C’est ce que fait l’hexagone de l’Application a travers des ports et des cas d’utilisation pour remplir ces fonctions.
L’hexagone du Framework fournit l’interface avec le monde extérieur. C’est l’endroit où nous avons la possibilité de déterminer comment exposer les fonctionnalités de l’application. C’est donc là que nous définissons les points de terminaison REST, GraphQl ou gRPC… Nous matérialisons les décisions technologiques par des adaptateurs.
Le diagramme suivant fournit une vue de haut niveau de l’architecture :
Par la suite, nous explorerons plus en détail les composants, les rôles et les structures de chaque hexagone à travers des exemples concrets.
Mise en pratique l’architecture hexagonale
Imaginons que vous soyez impliqué dans un projet visant à créer un blog où les utilisateurs peuvent publier des articles. L’objectif est de créer une structure de base pour démarrer le développement de votre application de blog en utilisant l’architecture hexagonale.
Domain hexagon
L’hexagone du domaine implique une démarche de compréhension et de modélisation d’un problème concret. Vous pouvez ne pas connaître le métier de votre application, pas de panique, comme le recommande le Domain-Driven Design : Tackling Complexity in the Heart of Software, s’attaquer à la complexité au cœur du logiciel, pour cela, il est nécessaire de consulter des experts du domaine ou d’autres développeurs qui connaissent déjà le problème, vous devez aussi essayer de combler le manque de connaissance en consultant des livres ou d’autres documents traitant du domaine.
À l’intérieur de l’hexagone du domaine, vous trouverez des entités, des objets de valeur et toutes les catégories d’objets que vous estimez nécessaires pour représenter le domaine. Voici une représentation basée uniquement sur les entités et les objets de valeur :
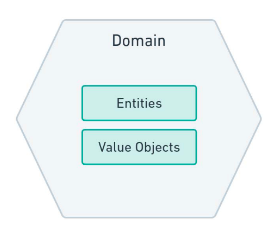
Analysons en détail les composants de cet hexagone.
Entities
Les entités nous aident à construire un code plus expressif. Ce qui caractérise une entité, c’est son sens de la continuité et de l’identité. Cette continuité est liée au cycle de vie et aux caractéristiques mutables de l’objet. Par exemple, dans notre scénario d’application, nous avons mentionné l’existence d’articles. Pour un article, nous pouvons définir un type technique ou scientifique.
Nous pouvons également attribuer certaines propriétés décrivant la relation qu’un article entretient avec d’autres objets. Toutes ces propriétés peuvent évoluer avec le temps, démontrant ainsi que l’article n’est pas un objet statique et que ses caractéristiques peuvent changer. C’est pourquoi nous pouvons affirmer qu’un article a un cycle de vie. Par ailleurs, chaque article doit être unique dans un blog, il doit donc avoir une identité. Ce sens de la continuité et de l’identité sont donc les éléments qui déterminent une entité.
Le code ci-dessous illustre une classe d’entité Article composée d’objets de valeur ArticleType et ArticleID :
public class Article {
private final ArticleId articleId;
private final ArticleType articleType;
public Article(ArticleId articleId, ArticleType articleType) {
this.articleId = articleId;
this.articleType = articleType;
}
public static Predicate<Article> filterByType(ArticleType articleType) {
return articleType.equals(ArticleType.TECHNICAL) ? isTechnical() : isScientific();
}
public static Predicate<Article> isTechnical() {
return article -> article.getArticleType() == ArticleType.TECHNICAL;
}
public static Predicate<Article> isScientific() {
return article -> article.getArticleType() == ArticleType.SCIENTIFIC;
}
public static List<Article> filter(List<Article> articles, Predicate<Article> predicate) {
return articles.stream()
.filter(predicate)
.collect(Collectors.toList());
}
public ArticleType getArticleType() {
return articleType;
}
}Value Objects
Les objets de valeur renforcent la lisibilité de notre code lorsque l’identification unique d’un objet n’est pas nécessaire, en particulier lorsque nous accordons plus d’importance aux attributs de l’objet qu’à son identité. Nous pouvons utiliser des objets valeur pour composer un objet entité, et nous devons donc rendre les objets valeur immuables afin d’éviter des incohérences imprévues dans le domaine. Dans l’exemple de l’article présenté précédemment, nous pouvons représenter le Type de l’Article comme un objet de valeur attribut de l’entité Article :
public enum ArticleType {
TECHNICAL,
SCIENTIFIC;
}Jusqu’à présent, nous avons discuté de la manière dont l’hexagone du domaine encapsule les règles de gestion avec des entités et des objets de valeur. Mais il existe des situations où le logiciel n’a pas besoin d’opérer directement au niveau du domaine. The Clean Architecture : A Craftsman’s Guide to Software Structure and Design indique que certaines opérations existent uniquement pour permettre l’automatisation fournie par le logiciel. Ces opérations, bien qu’elles soutiennent les règles de gestion, n’existeraient pas en dehors du contexte du logiciel. Il s’agit des des opérations spécifiques à l’application.
Application hexagon
L’hexagone de l’application est l’endroit où nous définissons les besoins de l’application en termes de fonctionnalités et de règles métier, sans nous préoccuper des détails technologiques de la mise en œuvre. Cela nous permet de rester focalisés sur les exigences du client ou de l’utilisateur final, tout en gardant une vision globale de l’ensemble du système.
Sur la base du même scénario de l’application de blog, supposons que vous ayez besoin d’afficher les articles du même type. Pour générer ces résultats, il serait nécessaire d’effectuer un traitement des données. Votre logiciel doit recueillir les informations de l’utilisateur afin de rechercher les types d’articles. Il se peut que vous souhaitez utiliser une règle de gestion particulière pour valider l’entrée de l’utilisateur et une règle de gestion pour vérifier les données extraites de sources externes. Si aucune contrainte n’est violée, votre logiciel fournit des données montrant une liste des articles de même type. Vous pouvez regrouper toutes ces tâches différentes dans un cas d’utilisation. Le diagramme suivant illustre la structure de haut niveau de l’hexagone application basée sur les cas d’utilisation, les ports d’entrée et les ports de sortie :
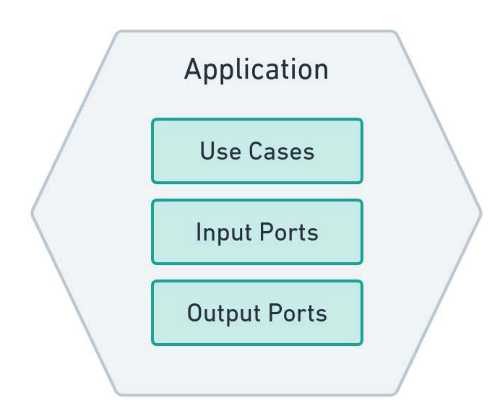
Analysons en détail les composants de cet hexagone.
Use Cases
Les cas d’utilisation représentent le comportement du système à travers des opérations spécifiques à l’application, conçues pour répondre aux exigences du domaine logiciel. Les cas d’utilisation peuvent interagir directement avec des entités et d’autres cas d’utilisation, ce qui en fait des composants flexibles. En Java, nous représentons les cas d’utilisation comme des abstractions définies par des interfaces exprimant ce que le logiciel peut faire. Le code suivant montre un cas d’utilisation qui fournit une opération permettant d’obtenir une liste filtrée d’articles :
public interface ArticleUseCase {
List<Article> getArticles(Predicate<Article> predicate);
}Notez le filtre Predicate. Nous allons l’utiliser pour filtrer la liste des articles lors de l’implémentation de ce cas d’utilisation avec un port d’entrée.
Input Ports
Si les cas d’utilisation décrivent simplement les fonctionnalités du logiciel, il est toujours nécessaire d’implémenter l’interface correspondante. C’est là que les ports d’entrée entrent en jeu. En tant que composants directement liés aux cas d’utilisation au niveau de l’application, les ports d’entrée nous permettent d’exécuter le comportement prévu du logiciel conformément à la sémantique du domaine. En d’autres termes, ils fournissent un moyen de traduire les entrées de l’utilisateur en actions qui peuvent être exécutées par le logiciel. Voici un port d’entrée fournissant une implémentation du cas d’utilisation ArticleUseCase :
public class ArticleInputPort implements ArticleUseCase {
private ArticleOutputPort articleOutputPort;
public ArticleInputPort(ArticleOutputPort articleOutputPort) {
this.articleOutputPort = articleOutputPort;
}
@Override
public List<Article> getArticles(Predicate<Article> predicate) {
var articles = articleOutputPort.fetchArticles();
return Article.filter(articles, predicate);
}
}Cet exemple illustre comment nous pouvons exploiter une contrainte de domaine pour nous assurer que nous sélectionnons les articles souhaités. En mettant en œuvre un port d’entrée (Input Port) conforme à l’interface du cas d’utilisation, nous pouvons également acquérir des informations à partir de sources externes. Ceci peut être réalisé par l’utilisation de ports de sortie (Output Port).
Output Ports
Dans certaines situations, un cas d’utilisation doit récupérer des données auprès de ressources pour atteindre ses objectifs. C’est le rôle des ports de sortie, qui sont représentés sous la forme d’interfaces décrivant, sans tenir compte de la technologie, le type de données qu’un cas d’utilisation ou un port d’entrée devrait obtenir de l’extérieur pour effectuer ses opérations. Les ports de sortie ne se soucient pas de savoir si les données proviennent d’une technologie de base de données relationnelle particulière ou d’un système de fichiers, par exemple. Nous attribuons cette responsabilité aux adaptateurs de sortie, que nous allons examiner plutard :
public interface ArticleOutputPort {
List<Article> fetchArticles();
}Examinons à présent le dernier type d’hexagone
Framework hexagon
L’organisation semble bien structurée, avec nos règles métier essentielles restreintes à l’hexagone du domaine, suivies par l’hexagone de l’application qui traite de certaines opérations spécifiques à l’application au moyen de cas d’utilisation, de ports d’entrée et de ports de sortie. Maintenant, il est temps de décider quelles technologies seront autorisées à interagir avec notre logiciel. Cette communication peut se faire sous deux formes, l’une connue sous le nom de driving et l’autre sous le nom de driven. Pour le côté pilote, nous utilisons des adaptateurs d’entrée, et pour le côté piloté, nous utilisons des adaptateurs de sortie, comme le montre le diagramme suivant :
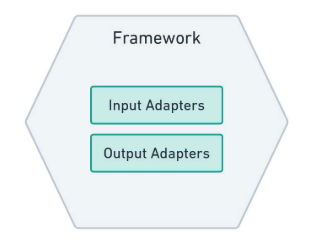
Examinons cela plus en détail.
Input Adapters
Les opérations de pilotage sont celles qui demandent des actions au logiciel. Il peut s’agir d’un utilisateur avec un client en ligne de commande ou d’une application frontale, par exemple. Il peut y avoir des suites de tests qui vérifient l’exactitude des éléments exposés par votre logiciel. Il peut également s’agir d’autres applications d’un vaste écosystème qui ont besoin d’interagir avec certaines fonctionnalités de votre logiciel. Cette communication s’effectue par l’intermédiaire d’une API construite au-dessus des adaptateurs d’entrée.
Cette API définit la manière dont les entités externes interagiront avec votre système et traduiront ensuite leur demande vers l’application de votre domaine. Le terme pilotage est utilisé parce que ces entités externes pilotent le comportement du système. Les adaptateurs d’entrée peuvent définir les protocoles de communication pris en charge par l’application, comme indiqué ici :
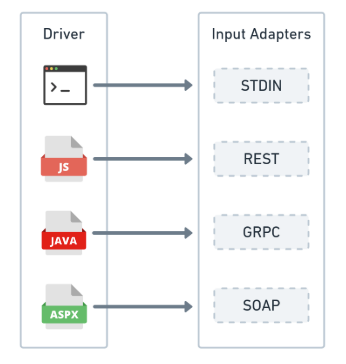
Supposons que vous ayez besoin d’exposer certaines fonctionnalités logicielles à des applications existantes qui fonctionnent uniquement avec SOAP sur HTTP/1.1 et que, dans le même temps, vous ayez besoin de mettre ces mêmes fonctionnalités à la disposition de nouveaux clients qui pourraient tirer parti des avantages de l’utilisation de gRPC sur HTTP/2. Avec l’architecture hexagonale, vous pourriez créer des adaptateurs d’entrée pour les deux scénarios. En utilisant des adaptateurs d’entrée spécifiques pour chaque scénario, vous pouvez facilement gérer les différences de formatage des données entre les systèmes d’information source et destination, ainsi que les transformations nécessaires pour les rapprocher de la représentation utilisée dans le domaine. Cela rend également plus simple la gestion des évolutions futures, car les modifications peuvent être apportées de manière isolée aux adaptateurs d’entrée sans affecter le reste de l’application.
public class ArticleCliInputAdapter {
private ArticleUseCase articleUseCase;
public ArticleCliInputAdapter() {
initAdapters();
}
private void initAdapters() {
this.articleUseCase = new ArticleInputPort(ArticleFileOutputAdapter.getInstance());
}
public List<Article> getArticlesByType(String type) {
return articleUseCase.getArticles(Article.filterByType(ArticleType.valueOf(type)));
}
}Cet exemple illustre la création d’un adaptateur d’entrée qui reçoit des données de STDIN. Notez l’utilisation du port d’entrée à travers son interface de cas d’utilisation. Ici, nous avons passé la commande qui encapsule les données d’entrée utilisées sur l’hexagone d’application pour traiter les contraintes du domaine. Si nous voulons activer d’autres formes de communication, telles que REST, il nous suffit de créer un nouvel adaptateur REST contenant les dépendances nécessaires pour exposer un point de terminaison de communication REST.
Output Adapters
De l’autre côté, nous avons les opérations pilotées. Ces opérations sont initiées par votre application et récupèrent les données requises du monde extérieur pour satisfaire les besoins du logiciel. Une opération pilotée se produit généralement en réponse à une opération motrice. Comme vous pouvez l’imaginer, la façon dont nous définissons le côté piloté est par le biais d’adaptateurs de sortie. Ces adaptateurs doivent se conformer à nos ports de sortie en les implémentant. Voici un diagramme des adaptateurs de sortie et des opérations pilotées :
| N’oubliez pas qu’un port de sortie nous indique le type de données dont il a besoin pour effectuer certaines tâches spécifiques à l’application. C’est à l’adaptateur de sortie de décrire comment il obtiendra les données. |
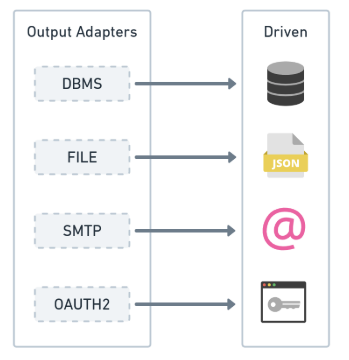
Imaginons que votre application ait initialement été configurée avec des bases de données relationnelles MySql et que, après un certain temps, vous ayez décidé de changer de technologie et de passer à une approche NoSQL, en adoptant MongoDB comme source de données. Au début, vous n’auriez qu’un seul adaptateur de sortie pour permettre la persistance avec les bases de données MySql.
Pour permettre la communication avec MongoDB, vous devez créer un adaptateur de sortie sur l’hexagone Framework, sans toucher aux hexagones Application et, surtout, du Domaine. Comme les adaptateurs d’entrée et de sortie pointent tous deux à l’intérieur de l’hexagone, nous les faisons dépendre à la fois de l’hexagone de l’application et de l’hexagone du domaine, inversant ainsi la dépendance.
Le terme "piloté" est utilisé parce que ces opérations sont pilotées et contrôlées par l’application hexagonale elle-même, ce qui déclenche des actions dans d’autres systèmes externes.
Notez dans l’exemple suivant comment l’adaptateur de sortie met en œuvre l’interface de port de sortie pour spécifier comment l’application va obtenir des données externes :
public class ArticleFileOutputAdapter implements ArticleOutputPort {
@Override
public List<Article> fetchArticles(){
return readFileAsString();
}
private List<Article> readFileAsString() {
// TODO implementation of the code
}
}Conclusion
L’architecture hexagonale offre une grande flexibilité pour supporter les exigences changeantes des entreprises et des projets, tout en garantissant une certaine cohérence et une meilleure compréhension de la structure du code. Grâce à cette approche, vous pouvez créer des applications plus solides, plus faciles à faire évoluer et à maintenir, et donc plus susceptibles de répondre aux besoins de vos clients ou de vos utilisateurs finaux.
Dans la deuxième partie, nous mettrons l’accent sur la manière de structurer un projet en utilisant une architecture hexagonale et de concrétiser la séparation des éléments dont nous avons discuté dans la première partie.
Sommaire :