Génération de contenus enrichis : Implémenter un système de RAG avec Spring AI

Ricken Bazolo
Référent technique
Publié le 05/04/2024
•Temps de lecture : 5 minutes

Génération de contenus enrichis : Implémenter un système de RAG avec Spring AI
Spring AI fournit une interface simple pour intégrer des fonctionnalités d’intelligence artificielle dans vos applications Spring Boot. Nous allons explorer le framework ETL (Extract, Transform, Load) de Spring AI et voir comment il peut être utilisé pour implémenter un système de RAG.
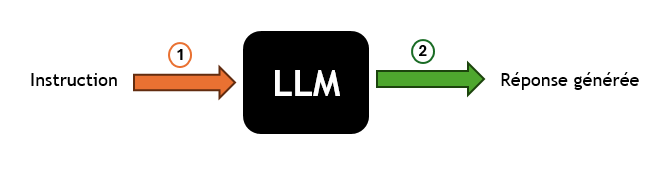
Dans une approche simple basée sur un modèle génératif, l’IA crée des réponses à partir d’un prompt donné, s’appuyant sur son corpus d’entraînement ou sur des informations préalablement connues.
-
(1): Une commande ou une requête est fournie au modèle. C’est l’étape où l’utilisateur interagit avec le système en posant une question ou en donnant une instruction spécifique. -
(2): Le LLM génère une réponse en fonction de l’instruction reçue. Cette réponse est basée sur les connaissances et les données qu’il a acquises pendant la phase d’entraînement.
| Les grands modèles de langage (LLM) sont de très grands modèles construits sur l’apprentissage automatique et pré-entraînés sur de grandes quantités de données, capable, entre autres tâches, de reconnaître et de générer du texte. Il représente le cœur du système d’IA, où l’instruction est traitée. |
Vous pouvez utiliser une implémentation de l’interface ChatClient fournie par le framework, pour mettre en œuvre cette approche avec Spring AI.
Pour utiliser Mistral AI avec Spring AI, vous devez ajouter la dépendance suivante à votre fichier pom.xml :
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mistral-ai-spring-boot-starter</artifactId>
</dependency>Voici un exemple de mise en œuvre avec l’implémentation MistralAiChatClient :
var response = chatClient.call(
new Prompt(
"Qu'elle est l'intrigue dans le premier volet de Spider-Man",
MistralAiChatOptions.builder()
.withModel(MistralAiApi.ChatModel.LARGE.getValue())
.build()
));Cependant, cette approche peut être limitée en termes de contexte et de pertinence. Pour surmonter ces limitations, l’approche RAG (Retrieval Augmented Generation) a été développée pour intégrer des connaissances externes dans le processus de génération de textes.
Qu’est-ce qu’un RAG (Retrieval Augmented Generation)
Le RAG est une technique qui enrichit les capacités des modèles de langage génératifs en leur permettant d’exploiter des données externes. Cela signifie qu’au lieu de se baser uniquement sur ce qu’ils ont appris durant leur phase d’entraînement, les modèles peuvent chercher et intégrer des informations provenant de sources de données spécifiques pour générer des réponses plus pertinentes et contextuelles.
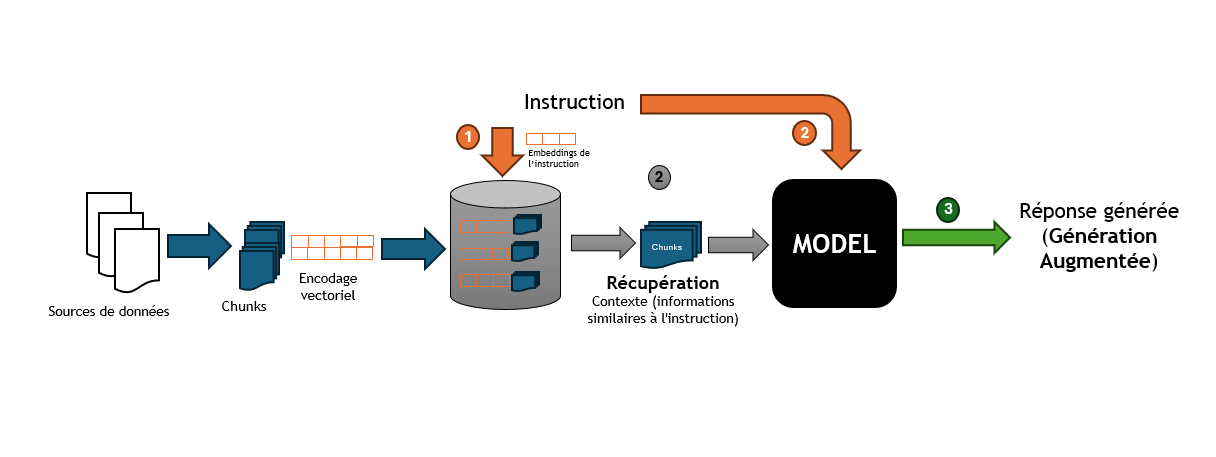
La Récupération (Retrieval)
La Récupération, représente la phase où le système récupère des informations pertinentes pour enrichir la réponse générée. Ces informations peuvent provenir de bases de données externes, de corpus de connaissances ou d’autres sources de données.
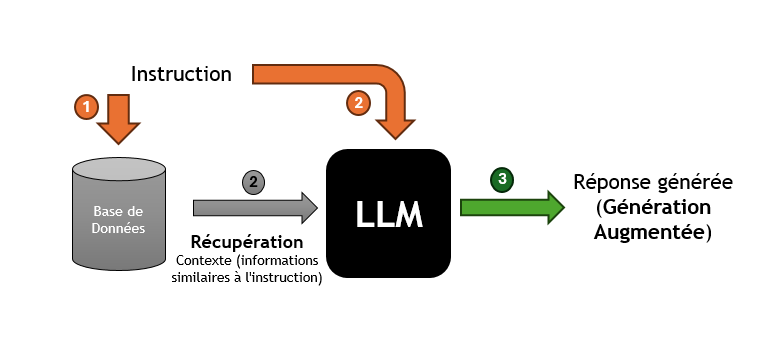
-
(1)&(2)- Instruction et Récupération du Contexte : Le système recherche, dans une base de données externe ou un corpus de connaissances, des informations pertinentes qui correspondent ou sont similaires à l’instruction initiale. Ces informations sont utilisées pour enrichir le contexte de la réponse. -
(3)- Génération Augmentée : Le LLM génère une réponse en fonction de l’instruction et des informations récupérées. Cette réponse est plus riche et plus contextuelle, car elle intègre des données externes.
| Avec l’instruction et le contexte récupéré, la réponse générée par le LLM est basée sur des informations contextuelles spécifiques qui ont été récupérées. |
La mise en œuvre de la "Récupération" avec Spring AI
Spring AI propose une API abstraite pour interagir avec les bases de données vectorielles, telles que PgVector via l’interface VectorStore.
Pour utiliser PgVector avec Spring AI, vous devez ajouter la dépendance suivante à votre fichier pom.xml :
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>La méthode similaritySearch de l’interface VectorStore permet de rechercher des informations pertinentes qui correspondent ou sont similaires à l’instruction initiale. Vous pouvez spécifier un seuil de similarité de 0 à 1.0 pour filtrer les résultats de la recherche et définir le nombre de résultats à renvoyer.
var similarity = vectorStore.similaritySearch(
SearchRequest.query("")
.withQuery(instruction)
.withSimilarityThreshold(0.1)
.withTopK(5));L’intégration d’une base de données, une révolution pour la génération de contenus enrichis, présente plusieurs avantages :
-
Accès à l’information en temps réel :
-
Alimentation du modèle avec des données fraîches et actualisées.
-
-
Personnalisation rapide et flexible :
-
Adaptation du contenu généré en fonction des besoins spécifiques de l’utilisateur.
-
Exploration et ajustement précis des données entrantes et sortantes.
-
-
Contrôle et intervention renforcés :
-
Surveillance et optimisation du processus de génération de textes.
-
Mise en place de mesures pour garantir la qualité et la pertinence des résultats.
-
Le Data Pipeline
Pour insérer les données dans la base de données, nous allons construire un data pipeline qui va extraire, transformer et charger les données dans la base de données vectorielles.
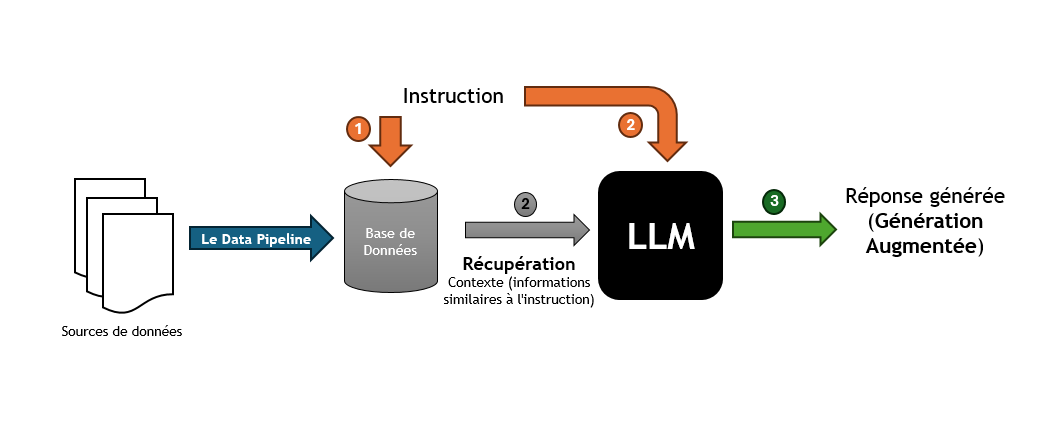
Les opérations spécifiques au RAG
Notre data pipeline doit être capable d’effectuer des opérations spécifiques au RAG. Ces opérations incluent : le chunking, la tokenisation, l'Embedding (Encodage vectoriel) et le stockage des données dans la base de données vectorielles.
Le Chunking
Le Chunking est une technique qui consiste à découper les données en morceaux plus petits pour les rendre plus faciles à traiter. Ces chunks peuvent être des phrases, des paragraphes ou des sections de texte qui vont être stockés dans la base de données vectorielles.
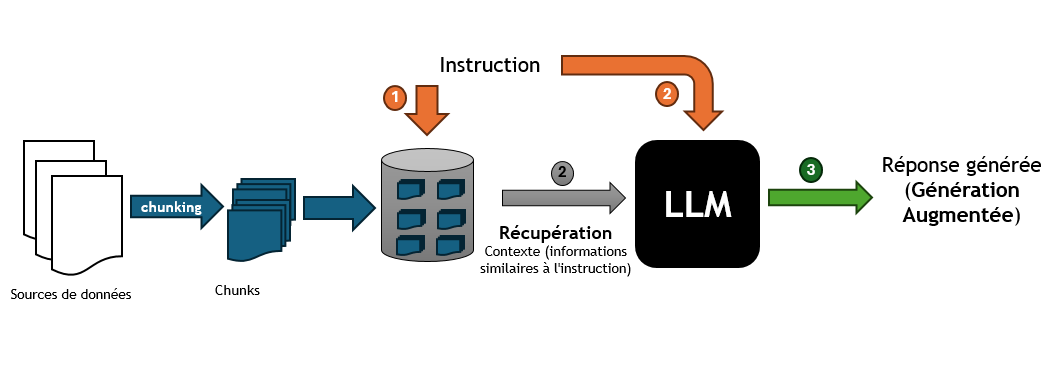
Spring AI fournit la classe TokenTextSplitter pour effectuer le chunking des données. Vous pouvez utiliser cette classe pour découper les données en chunks et les stocker dans la base de données vectorielles.
var textSplitter = new TokenTextSplitter();
var chunks = tokenTextSplitter.split(texts, 2048); (1)| 1 | La méthode split fait le chunking, vous pouvez spécifier la taille du chunk. |
La Tokenisation
Pour un RAG, la tokenisation joue un rôle crucial, car elle est la première étape permettant au modèle de comprendre et de manipuler le texte. Des tokens incorrectement définis peuvent mener à une récupération d’informations inefficaces et à des réponses générées qui ne sont pas pertinentes ou précises.
Spring AI s’appuie sur la librairie JTokkit pour effectuer la tokenisation des données. Vous pouvez utiliser la classe TokenTextSplitter pour la tokenisation et le chunking.
var tokenTextSplitter = new TokenTextSplitter();
var chunks = tokenTextSplitter.apply(documents); (1)| 1 | La méthode apply fait la tokenisation et le chunking. |
L’encodage vectoriel (Embedding)
Un Embedding est un vecteur numérique dense représentant des tokens, des chunks, ou même des documents entiers, dans un espace vectoriel continu. Chaque dimension de l’embedding capte un aspect sémantique ou contextuel du contenu qu’il représente. Ce format encodé permet de traduire le texte en une forme que les algorithmes d’apprentissage automatique peuvent traiter efficacement.
Nous allons générer un embedding pour chaque chunk, et le stocker dans la base de données vectorielles.
Il est important de noter que la génération de l’embedding de l’instruction initiale sera utilisée pour la recherche de similarité.
| Pourquoi a t-on besoin d’un encodage vectoriel ? Les vecteurs numériques offrent une méthode de comparaison rapide, efficace et économique, ce qui les rend idéaux pour identifier et récupérer les segments (chunks) de texte pertinent dans notre base de données. |
Spring AI fournit une API abstraite pour générer des embeddings via l’interface EmbeddingClient.
Pour générer un embedding avec Spring AI en utilisant un modèle de Mistral AI, vous devez ajouter la dépendance suivante à votre fichier pom.xml :
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mistral-ai-spring-boot-starter</artifactId>
</dependency>Voici un exemple de mise en œuvre :
var embeddingResponse = embeddingClient.call(
new EmbeddingRequest(List.of("Hello World", "World is big and salvation is near"),
MistralAiEmbeddingOptions.builder()
.withModel("Different-Embedding-Model-Deployment-Name")
.build()));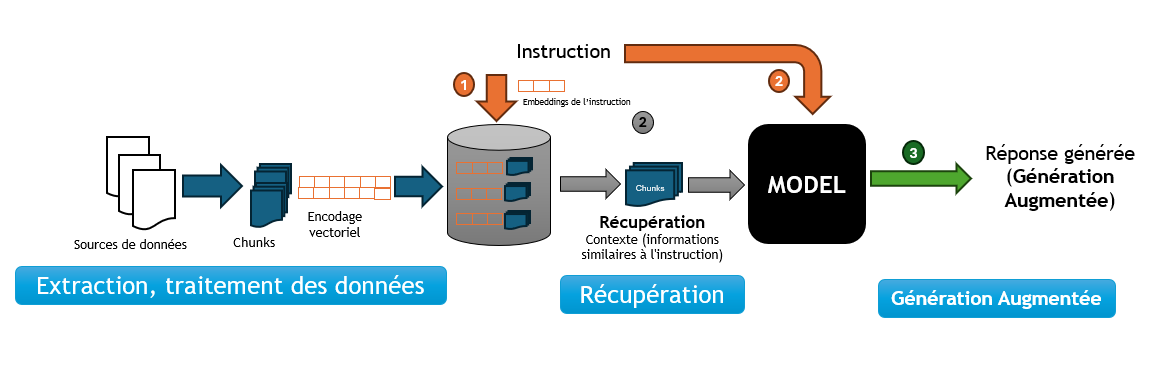
L’implémentation du système RAG
Créer un projet Spring Boot et ajouter les dépendances nécessaires à votre fichier pom.xml.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mistral-ai-spring-boot-starter</artifactId>
</dependency>Cette dépendance permet d’utiliser les modèles de Mistral AI pour créer un assistant conversationnel multilingue et générer des embeddings.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>Cette dépendance permet d’utiliser PgVector comme base de données vectorielles pour stocker les chunks et les embeddings.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>Ces dépendances permettent de lire et de traiter les documents PDF et les documents texte avec Apache Tika.
Créer une classe RagService qui va gérer les opérations spécifiques au RAG.
@Service
public class RagService {
@Autowired
private MistralAiChatClient chatClient;
@Autowired
private VectorStore vectorStore;
}La configuration de PgVector
Nous allons utiliser la configuration de base de PgVector avec Spring AI pour stocker les chunks et les embeddings dans la base de données vectorielles.
@Bean
public PgVectorStore pgVectorStore(JdbcTemplate jdbcTemplate, EmbeddingClient embeddingClient) {
return new PgVectorStore(jdbcTemplate, embeddingClient, 1536);
}Pour plus d’informations sur la configuration de PgVector, consultez la documentation officielle ici
L’extraction et traitement des données
Nous allons maintenant lire un document PDF et extraire les données pour les traiter avec notre système RAG.
public void processDocument(Ressource pdfDocument) {
var documents = new PagePdfDocumentReader(pdfDocument,
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(
ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build()); (1)
var tokenTextSplitter = new TokenTextSplitter();
var chunks = tokenTextSplitter.apply(docs); (2)
vectoreStore.accept(chunks); (3)
}| 1 | Extraction de données : Utilisation de la classe PagePdfDocumentReader pour extraire les données d’un document PDF. |
| 2 | Chunking : Utilisation de la classe TokenTextSplitter pour la tokenisation et découper les données en chunks. |
| 3 | Stockage des données : Stockage des chunks et des embeddings dans la base de données vectorielles. |
La récupération des informations (Retrieval)
Nous allons maintenant implémenter la recherche de similarité pour récupérer des informations pertinentes en fonction de l’instruction initiale.
public List<Documents> retrieveInformation(String instruction) {
return vectorStore.similaritySearch( (1)
SearchRequest.query("")
.withQuery(instruction) (2)
.withSimilarityThreshold(0.1) (3)
.withTopK(5)); (4)
}| 1 | Recherche de similarité : Utilisation de la méthode similaritySearch de la classe VectorStore pour rechercher des informations pertinentes en fonction de l’instruction initiale. |
| 2 | Embedding de l’instruction utilisée pour la recherche de similarité. L’embedding de cette instruction est généré lors de la phase de construction de la requête de recherche. |
| 3 | Seuil de similarité : Spécification d’un seuil de similarité pour filtrer les résultats de la recherche. Une valeur seuil de 0,0 signifie que toute similarité est acceptée ou désactive le filtrage par seuil de similarité. Une valeur de seuil de 1,0 signifie qu’une correspondance exacte est requise. |
| 4 | Nombre de résultats : Spécification du nombre de résultats a renvoyé. Cela permet de limiter le nombre de résultats retournés par la recherche. |
La Génération Augmentée
Nous allons maintenant générer une réponse en fonction de l’instruction et des informations récupérées.
public String generateResponse(String instruction) {
var documents = retrieveInformation(instruction); (1)
var systemMessage = new SystemPromptTemplate(
"""
Context information is below.
CONTEXT: {context}
Given the context information and not prior knowledge, answer the question in the same language.
QUESTION: {question}
"""
).createMessage(Map.of("question", instruction, "context", documents)); (2)
var userMessage = new UserMessage(message); (3)
var prompt = new Prompt(List.of(systemMessage, userMessage),
MistralAiChatOptions.builder()
.withModel(MistralAiApi.ChatModel.LARGE.getValue())
.build()); (4)
return chatClient.stream(prompt); (5)
}| 1 | Récupération des informations : Utilisation de la méthode retrieveInformation pour récupérer des informations pertinentes en fonction de l’instruction initiale. |
| 2 | Création du message système : Création d’un message système qui contient les informations contextuelles récupérées et l’instruction initiale. |
| 3 | Création du message utilisateur à partir de l’instruction initiale. |
| 4 | Création du prompt : Création d’un prompt qui contient le message système et le message utilisateur. |
| 5 | Génération Augmentée de la réponse : Le prompt est ensuite transmis au ChatClient pour obtenir une réponse générative qui est retournée à l’utilisateur. |
| Les messages ayant le rôle d’utilisateur proviennent de l’utilisateur final ou du développeur. Ils représentent des questions, des invites ou toute autre entrée que vous souhaitez que le générateur réponde. Le message système donne des instructions de haut niveau pour la conversation. Ce rôle fournit généralement des instructions de haut niveau pour la conversation. Par exemple, vous pouvez utiliser un message système pour demander au générateur de se comporter comme un certain personnage ou de fournir des réponses dans un format spécifique. |
La classe RagService est maintenant prête à être utilisée pour générer des réponses enrichies en fonction de l’instruction initiale.
@Service
public class RagService {
@Autowired
private MistralAiChatClient chatClient;
@Autowired
private VectorStore vectorStore;
public void processDocument(Ressource pdfDocument) {
var documents = new PagePdfDocumentReader(pdfDocument,
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(
ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
var tokenTextSplitter = new TokenTextSplitter();
var chunks = tokenTextSplitter.apply(docs);
vectoreStore.accept(chunks);
}
public List<Documents> retrieveInformation(String instruction) {
return vectorStore.similaritySearch(
SearchRequest.query("")
.withQuery(instruction)
.withSimilarityThreshold(0.1)
.withTopK(5));
}
public String generateResponse(String instruction) {
var documents = retrieveInformation(instruction);
var systemMessage = new SystemPromptTemplate(
"""
Les informations contextuelles sont indiquées ci-dessous.
CONTEXT: {context}
Compte tenu des informations contextuelles et sans connaissances préalables, répondez à la question.
QUESTION: {question}
"""
).createMessage(Map.of("question", instruction, "context", documents));
var userMessage = new UserMessage(message);
var prompt = new Prompt(List.of(systemMessage, userMessage),
MistralAiChatOptions.builder()
.withModel(MistralAiApi.ChatModel.LARGE.getValue())
.build());
return chatClient.stream(prompt);
}
}Conclusion
Le module Spring AI fournit une interface simple pour intégrer des fonctionnalités d’intelligence artificielle dans vos applications Spring Boot. L’approche RAG (Retrieval Augmented Generation) permet d’enrichir la création de contenu et l’analyse contextuelle grâce à l’intégration dynamique de connaissances externes. En combinant Spring AI et PgVector ou d’autres base de données vectorielle supportées par Spring AI, vous pouvez construire un système RAG complet qui génère des réponses plus riches et plus contextuelles en fonction de l’instruction initiale.
Sommaire :