record Distance(float value) {}Valhalla & Value Types au pays des fractales

Clément de Tastes
Tech Lead
Publié le 22/09/2025
•Temps de lecture : 12 minutes

Valhalla & Value Types au pays des fractales
Nous vous proposons de faire un saut dans le futur de Java, plus particulièrement au travers d’améliorations que le projet Valhalla nous prépare. Nous en profiterons pour les mettre en pratique sur un exemple parlant : le calcul et la visualisation de l’ensemble de Mandelbrot.
Types objets vs primitifs
Les programmes Java font cohabiter objets et types primitifs. Les premiers offrent la richesse de l’abstraction tandis que les seconds se démarquent par leur performance.
Si l’on définit le type Distance comme étant une simple encapsulation d’un float :
On pourra bénéficier de certains avantages :
-
Une
Distancen’est pas uneSpeedpar exemple. En manipulant de simplesfloaton pourrait accidentellement passer la mauvaise valeur à une méthode ou ajouter entre elles des données n’étant pas compatibles -
On peut enrichir le type
Distancede méthodes, par exempleadd(Distance other)ou surchargertoString()pour afficher l’unité -
Il est possible de réaliser un contrôle d’intégrité dans le constructeur, en levant par exemple une
IllegalArgumentExceptionsi la valeur est négative -
…
Mais ceci a un coût, prenons le cas de la méthode add() :
record Distance(float value) {
public Distance add(Distance other) {
return new Distance(value + other.value);
}
}Une nouvelle instance de Distance est créée à chaque appel ce qui accentue la pression sur le garbage collector.
Dans le cas d’un tableau, Distance[] pâtit de quelques surcoûts par rapport à float.
Quand float[] est en mémoire un tableau contigu de valeurs primitives, Distance[] est un tableau d’objets, donc de pointeurs.
Chaque objet référencé possède son propre header, ainsi que potentiellement quelques octets d’alignement.
La densité mémoire est donc bien moins bonne, comme l’illustre ce schéma.
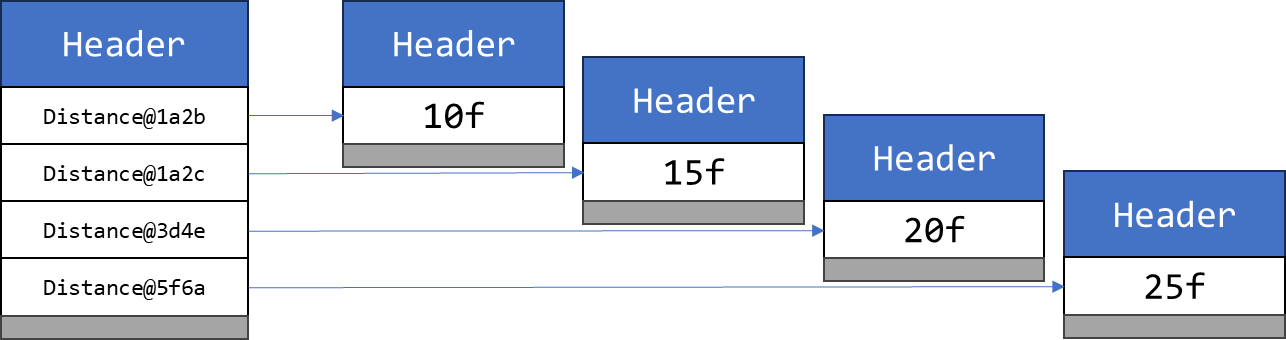
L’accès est également plus lent, car il passe par des références. Dans une boucle par exemple, le CPU doit suivre ces indirections une à une. Ce pointer chasing est coûteux, parce que les objets référencés peuvent être dispersés en mémoire, ce qui entraîne des cache misses et des lectures en RAM, beaucoup plus lentes.
On a donc une perte sur les performances d’accès et sur l’empreinte mémoire.
Le projet Valhalla
Projet ambitieux, Valhalla a pour but de fournir une forme d’unification des types objets et primitifs par le biais d’une nouvelle famille d’objets : les Value Types.
Il s’agit d’objets sans identité dont les champs sont final.
Ce renoncement à l’identité va permettre à la JVM un certain nombre d’optimisations.
Dire qu’il s’agit d’un projet au long cours est un euphémisme : Valhalla a été annoncé officiellement par Oracle en 2014 et est toujours en développement actif. Son échelonnement est composé de 5 grandes étapes successives :
-
JEP 401: Value Classes and Objects : introduction des Value Types
-
JDK-8303099: Null-Restricted and Nullable Types : ajout de la possibilité de déclarer qu’un type rejette ou accepte délibérément la valeur
null -
JDK-8316779: Null-Restricted Value Class Types : amélioration des performances des champs et tableaux utilisant des Value Types non-nullables
-
JEP 402: Enhanced Primitive Boxing : permettre de traiter les types primitifs de manière plus proche de celle des objets
-
Parametric JVM : conserver et optimiser les paramétrages de classes et méthodes génériques à l’exécution
La première étape, dont nous allons parler dans cet article, n’est encore dans aucune version du JDK standard, ni même en preview. On peut sans prendre de gros risques parier qu’il faudra encore plusieurs années avant de voir toutes ces fonctionnalités délivrées en standard, et possiblement sous une forme différente que celle présentée.
Il est néanmoins possible d’expérimenter une partie de ces fonctionnalités avec un build du JDK contenant les travaux de la branche Valhalla du projet OpenJDK. Pour cela, deux possibilités :
-
Utiliser un build early-access pour votre plateforme, par exemple depuis https://jdk.java.net/valhalla (version Windows datée) ou https://builds.shipilev.net/openjdk-jdk-valhalla (Linux uniquement)
-
Builder vous-même le JDK à partir des sources https://github.com/openjdk/valhalla, branche
lworld
Le mot clé value
Un nouveau mot clé contextuel fait son apparition dans le langage : value.
Il peut être positionné avant la déclaration d’une classe ou d’un record : value class ou value record.
Pour modéliser un nombre complexe composé de sa partie réelle re et de sa partie imaginaire im :
public value class Complex {
private double re;
private double im;
public Complex(double re, double im) {
this.re = re;
this.im = im;
}
/* Getters, hashCode, equals, ... */
}Ou autrement avec un record :
public value record Complex(double re, double im) {}Caractéristiques des Value Types
Un value object ne possède pas d’identité.
Contrairement à un objet standard pour lequel on possède une référence qui "l’identifie", un value object est caractérisé par ses valeurs.
Cela reste un java.lang.Object qui peut implémenter des interfaces ou fournir des méthodes, mais néanmoins, cette absence d’identité entraîne un certain nombre de conséquences.
Immutabilité et interchangeabilité
Il n’est pas possible de muter un value object : ses champs sont implicitement final.
Et à moins de le déclarer abstract, il est implicitement final : on ne peut pas l’étendre ni surcharger ses méthodes.
Deux instances d’un value type sont considérées comme étant interchangeables si leurs champs ont les mêmes valeurs. Leur état est fixé et immuable, elles représentent la même valeur de domaine, aussi bien maintenant que dans le futur. En termes de sémantique, l’une ou l’autre des deux instances peut être utilisée indifféremment. La JVM est d’ailleurs libre de n’utiliser qu’une seule instance dans ce cas.
Synchronisation
Une autre conséquence directe de cette absence d’identité est qu’il n’est pas possible d’utiliser un bloc synchronized sur un value object.
var origin = new Complex(0, 0);
synchronized (origin) {
//
}Un tel cas d’usage provoque l’erreur de compilation :
Unexpected type
required: a type with identity.
Cela ne se limite pas à la compilation : au runtime, la JVM vérifie que le type possède une identité.
var origin = new Complex(0, 0);
Object o = origin;
synchronized (o) {
//
}Ce code compile, mais lève une java.lang.IdentityException à l’exécution :
java.lang.IdentityException: Cannot synchronize on an instance of value class
Comparaison avec ==
La comparaison avec == prend un tout autre sens avec les value types.
D’ordinaire, == compare les références des objets (les identity objects, objets habituels déclarés sans le mot clé value).
Avec les value types, == effectue une comparaison sur tous les champs.
Ainsi, le code suivant affichera "true" bien que l’on ait créé deux instances, car les champs sont comparés deux-à-deux :
var c1 = new Complex(1, 2);
var c2 = new Complex(1, 2);
IO.println(c1 == c2); (1)| 1 | java.lang.IO permet d’interagir avec la console un peu plus simplement que le traditionnel System.out, cf. JEP 512: Compact Source Files and Instance Main Methods, standard en Java 25 |
HashCode avec System.identityHashCode()
La méthode System.identityHashCode() renvoie la valeur qu’aurait renvoyé un appel à la méthode hashCode(), que la méthode soit surchargée ou non.
La JVM HotSpot génère et stocke cet identity hash code dans le header de l’objet, une fois qu’il a été généré.
Pour un value object, le comportement diffère, en toute logique : le calcul se base sur le contenu (la valeur des champs), sans pour autant renvoyer forcément une valeur identique à celle renvoyée par hashCode().
IO.println(c1.hashCode() + " " + System.identityHashCode(c1));
IO.println(c2.hashCode() + " " + System.identityHashCode(c2));Affichage dans la console
-32505856 507117229 -32505856 507117229
Utilisation de WeakReference
Une java.lang.ref.WeakReference n’a de sens que si la référence cible possède une identité d’objet, que l’on peut pointer en mémoire et que le garbage collector peut suivre.
Il n’est donc pas possible de créer une instance de WeakReference à partir d’un value object.
Le code suivant lève une
java.lang.IdentityExceptionvar c = new Complex(1, 2);
var ref = new WeakReference<>(c1);Initialisation stricte
Avant de continuer à parler des value objects, faisons un pas de côté pour nous pencher sur une évolution récente du JDK.
La JEP 513 : Flexible Constructor Bodies, qui entre en standard dans Java 25, vient lever quelques restrictions liées à la construction des objets.
Il est désormais possible, dans le corps d’un constructeur, d’insérer des instructions avant l’appel explicite à super() ou this().
Ces instructions ne peuvent pas faire référence à l’objet en cours de construction, mais elles peuvent initialiser ses champs ou effectuer d’autres traitements.
On peut, par exemple, valider les arguments en amont et ne procéder à la création de l’objet que s’ils sont valides, évitant ainsi des traitements inutiles.
public class Point3D extends Point2D {
private double z;
public Point3D(double x, double y, double z) {
// Prologue (1)
if (Double.isNaN(z)) {
throw new IllegalArgumentException("z shall be a number");
}
super(x, y);
// Epilogue (2)
this.z = z;
}
}| 1 | La partie située avant l’appel à super / this est appelée prologue |
| 2 | La partie située après l’appel à super / this est appelée epilogue |
Lorsqu’un champ est initialisé dans le prologue (avant l’appel à super / this) on dit que son initialisation est stricte.
Il n’est pas possible d’observer un état non initialisé dans ce cas.
Revenons aux value types : cette initialisation stricte s’y impose : tous les champs doivent être initialisés au sein du prologue.
Le code suivant ne compile pas :
public value class Complex {
private double re;
private double im;
Complex(double re, double im) {
super();
this.re = re;
this.im = im;
}
}Erreur de compilation
strict field re is not initialized before the supertype constructor has been called
Si l’on omet l’appel explicite à super(), alors il sera implicitement appelé après les initialisations.
Sérialisation
La sérialisation fonctionne nativement avec les types value record.
Mais pour les types value class, elle nécessite une attention particulière.
Concrètement, les value classes qui implémentent Serializable doivent définir les méthodes writeReplace() et readResolve().
Ces méthodes permettent de sérialiser et désérialiser un objet de remplacement à la place du value object lui-même.
Sans leur implémentation, toute tentative de sérialisation ou déserialisation échouera en levant une InvalidClassException.
La nécessité de ces méthodes vient du fait que les value classes ont leurs champs strictement initialisés, et que la déserialisation ne garantit pas l’initialisation sûre de ces champs.
Un value object ne peut être créé et initialisé que via un constructeur.
À l’avenir, des améliorations du mécanisme de sérialisation devraient permettre de sérialiser et désérialiser automatiquement une value class qui implémente Serializable.
| Si le sujet vous intéresse, Brian Goetz et Viktor Klang ont présenté lors de Devoxx 2024 le chemin vers une refonte des mécanismes de sérialisation, dont Valhalla pourrait bénéficier. La conférence est disponible via ce lien. |
Nouvelles API
Quelques nouvelles API sont ajoutées au JDK :
-
Class::isIdentityetClass::isValuerenvoient chacune un booléen qui indique s’il s’agit respectivement d’un identity type ou d’un value type -
Objects::isValueObjectindique si l’instance passée en paramètres est un value object -
Objects::requireIdentitylève uneIdentityExceptionsi l’objet passé en paramètres ne possède pas d’identité (est un value object)
var c = new Complex(3, 4);
IO.println(c.getClass().isIdentity()); // false
IO.println(c.getClass().isValue()); // true
IO.println(Objects.isValueObject(c)); // true
IO.println(Objects.requireIdentity(c)); // lève une IdentityExceptionChangements dans le JDK
Depuis le JDK 8, un certain nombre de classes du JDK ont été annotées @ValueBased, indiquant de leur caractère final, immuable, et de la vigilance à avoir quant à ne pas se reposer sur leur identité (==, synchronized, …), cf. Value-Based Classes.
Depuis le JDK 16 et la JEP 390: Warnings for Value-Based Classes, le compilateur javac implémente une nouvelle catégorie d’avertissement qui identifie les utilisations de l’instruction synchronized avec un opérande d’un type de classe annoté @ValueBased, ou d’un type dont tous les sous-types sont spécifiés comme étant @ValueBased.
Depuis le JDK 16
Integer i1000 = 1_000;
synchronized (i1000) { // ⚠️ warning
//
}Warning
Synchronization on instance of value-based class
Avec Valhalla, ce ne sont plus des warnings, mais des erreurs de compilation ou IdentityException levées au runtime, comme vu précédemment.
Également, de nombreuses classes @ValueBased deviennent des value classes, parmi lesquelles :
-
Dans
java.lang:Integer,Long,Float,Double,Character, … -
Dans
java.util:Optional,OptionalInt, … -
Dans
java.time:LocalDate,LocalDateTime, …
Cette liste sera amenée à être étendue, avec notamment les implémentations de List.of(), List.copyOf(), Set.of(), …
Avec Valhalla
Integer i1000 = 1_000;
synchronized (i1000) { // ❌ erreur
//
}Erreur de compilation
unexpected type required: a type with identity found: java.lang.Integer
Mise en pratique
Il est temps de mettre œuvre les value types dans un exemple concret.
Nous vous proposons de calculer et représenter l’ensemble de Mandelbrot, aux motifs fractales célèbres, qui implique un calcul mathématique récursif sur les nombres complexes. Si vous êtes curieux, plus d’informations sont disponibles sur la page Wikipedia qui lui est consacrée.
L’algorithme
L’ensemble de Mandelbrot est défini de la façon suivante :
\[\mathcal{M}=\left\{\, c\in\mathbb{C}\ \middle|\ \text{la suite }
\begin{cases}
z_0=0,\\
z_{n+1}=z_n^2+c
\end{cases}
\text{ est bornée} \right\}\]
Pour des raisons pratiques, on limitera le calcul à un certain nombre d’itérations, par exemple maxIterations = 255.
Il est démontré que dès lors que \(|z_n|\gt 2\) (ou de manière équivalente \(|z_n|^2 > 4\)), la suite n’est pas bornée, car la valeur du module tend vers l’infini.
On considère par approximation dans notre algorithme qu’un nombre complexe appartient à l’ensemble de Mandelbrot si après les maxIterations itérations, \(|z_n|^2\le 4\).
Exemple de point appartenant à l’ensemble de Mandelbrot
À partir du complexe [re0, im0], on calcule n itérations que l’on représente.
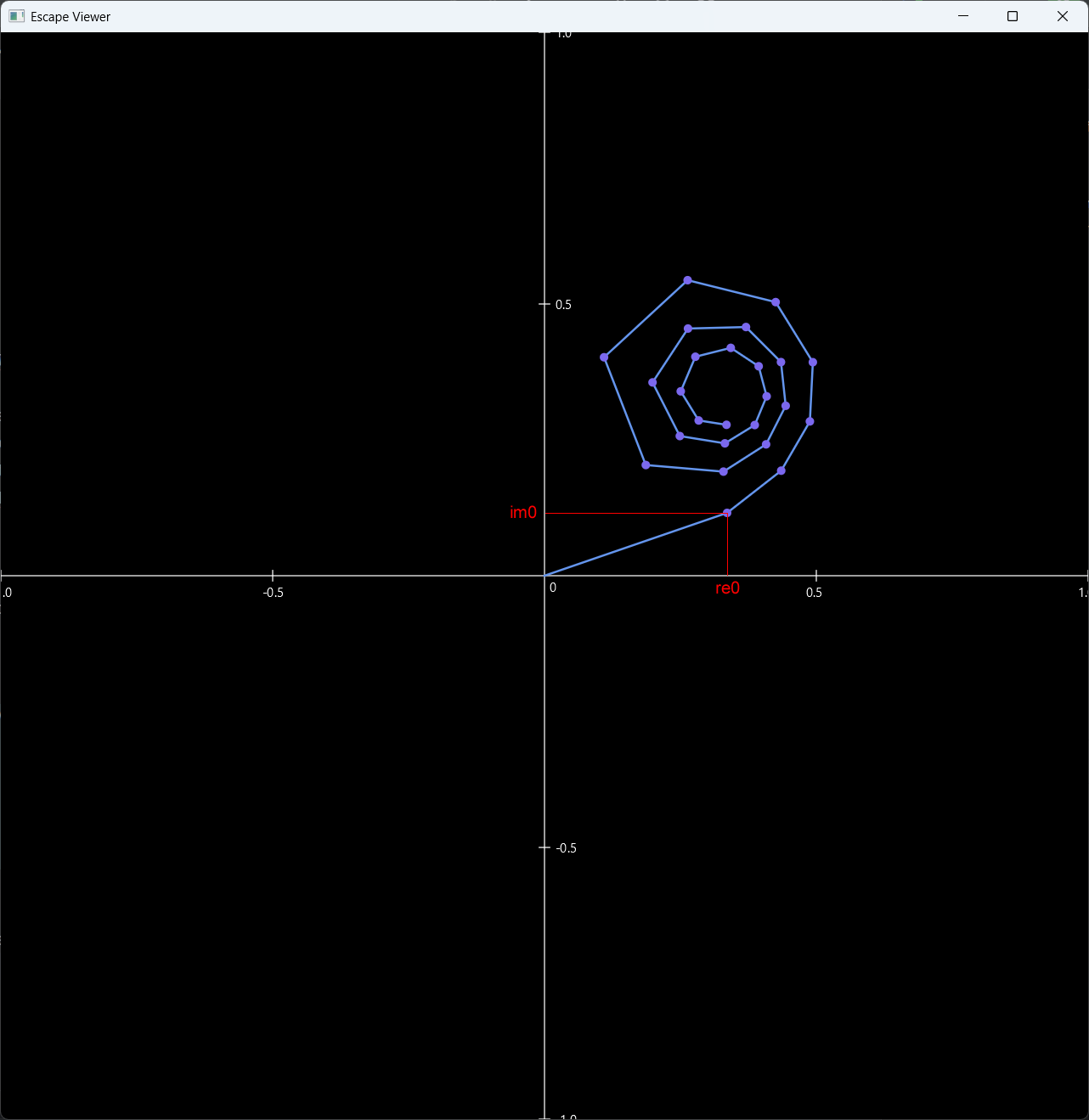
On voit les itérations former successivement une spirale
Exemple de point n’appartenant pas à l’ensemble de Mandelbrot
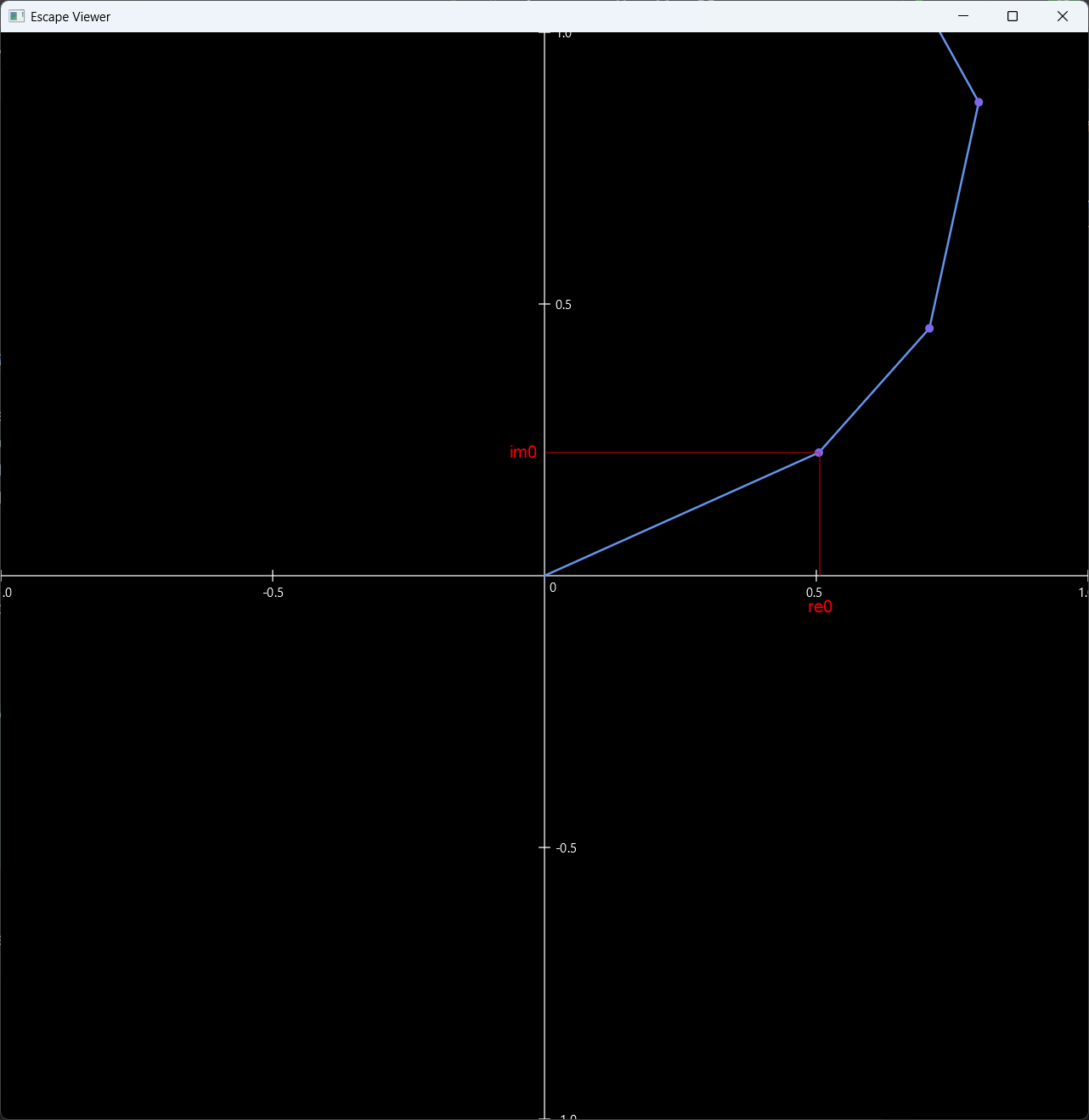
On voit les itérations "fuir", puis rapidement \(|z_n|^2 > 4\)
Calcul avec les types primitifs
Si l’on veut un calcul efficace et rapide avec une faible empreinte mémoire, on utilise naturellement des primitifs, des double en l’occurrence.
Voici le code que l’on peut écrire :
public int compute(double re0, double im0, int maxIterations) {
double re = 0;
double im = 0;
// Squared values
double re2 = 0;
double im2 = 0;
double modulus2 = 0;
// Iteration
int i = 0;
// (a + ib)(a + ib) = a² − b² + 2iab
while (modulus2 <= 4 && i < maxIterations) {
im = 2 * re * im + im0;
re = re2 - im2 + re0;
re2 = re * re;
im2 = im * im;
modulus2 = re2 + im2;
i++;
}
return i; (1)
}| 1 | On renvoie le nombre d’itérations, qui indique une "vitesse" de fuite, ce qui nous permettra de colorer l’ensemble en fonction lors du rendu |
Visualisation
En appliquant l’algorithme sur les points du plan, on peut générer une visualisation (ici, avec JavaFX).

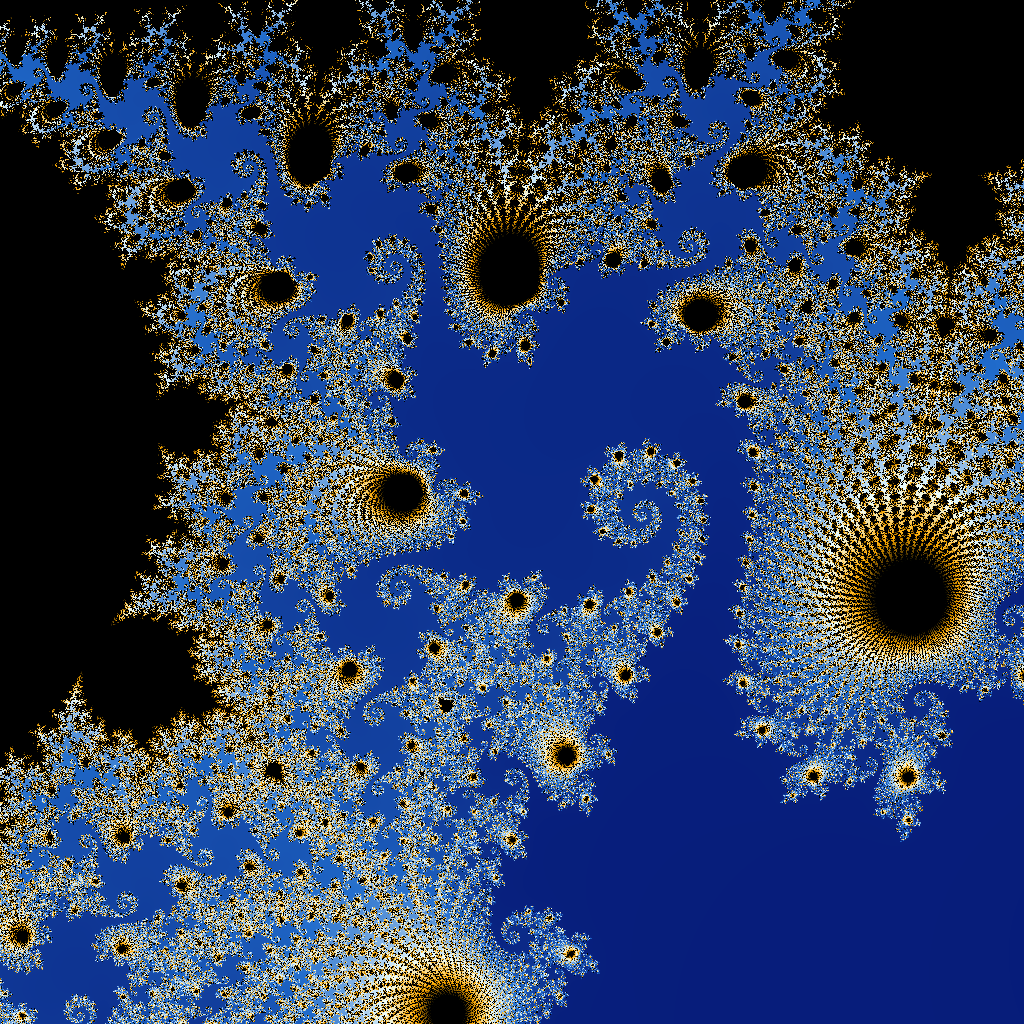
Abstraction et simplification du calcul
On peut drastiquement simplifier l’algorithme en tirant profit de l’abstraction que nous offre la programmation orientée objet.
On peut définir un objet Complex et des méthodes ad-hoc pour réaliser les calculs.
On définit ainsi 3 méthodes :
-
add()pour ajouter la valeur d’un autre nombre complexe -
square()pour élever le complexe au carré -
magnitudeSquared()pour calculer le carré du module
public record Complex(double re, double im) {
public Complex add(Complex other) {
return new Complex(re + other.re(), im + other.im());
}
public Complex square() {
return new Complex(re * re - im * im, 2 * re * im);
}
public double magnitudeSquared() {
return re * re + im * im;
}
}Une fois défini, on réécrit l’algorithme :
public int compute(double re, double im, int maxIterations) {
Complex c = new Complex(re, im);
Complex z = new Complex(0, 0);
int i = 0;
while (z.magnitudeSquared() < 4 && i < maxIterations) {
z = z.square().add(c);
i++;
}
return i;
}L’algorithme est tout de suite nettement plus clair, lisible et maintenable. On voit apparaître clairement notre formule \(z_{n+1} = z_n^2 + c\).
Performances
Malheureusement, ce qui est beau est cher.
Alors que sur notre machine de test, il faut un peu moins de 40ms pour générer notre image avec les types primitifs, il faut plus de 400ms soit plus de 10x plus de temps pour générer l’image avec l’objet Complex.
Ceci impacte négativement l’expérience utilisateur lorsque l’on navigue dans l’ensemble (zoom, translation) puisqu’il faut sans cesse recalculer l’image.
Calculs avec types primitifs
Mandelbrot.update 48 - Rendered in : 35.3604ms Mandelbrot.update 49 - Rendered in : 37.9037ms Mandelbrot.update 50 - Rendered in : 38.235ms Mandelbrot.update 51 - Rendered in : 38.2597ms
Calculs avec l’objet
ComplexMandelbrot.update 52 - Rendered in : 471.137ms Mandelbrot.update 53 - Rendered in : 454.612ms Mandelbrot.update 54 - Rendered in : 399.3353ms Mandelbrot.update 55 - Rendered in : 400.4051ms
L’allocation d’une nouvelle instance de Complex a chaque calcul induit un surcoût non négligeable.
Les Values Types à la rescousse
Notre objet Complex, comme il est défini, est un très bon candidat pour devenir un value type.
Modifions le en ajoutant simplement le mot clé value :
public value record Complex(double re, double im) {
/* reste inchangé */
}Calculs avec un
value recordMandelbrot.update 61 - Rendered in : 42.7773ms
Mandelbrot.update 62 - Rendered in : 38.7922ms
Mandelbrot.update 63 - Rendered in : 40.2715ms
Mandelbrot.update 64 - Rendered in : 39.0684msOn retrouve des performances analogues à celles des primitifs, tout en conservant notre abstraction. Le meilleur des deux mondes !
Java Flight Recorder
Réalisons un enregistrement JFR afin de comparer les allocations mémoire des différents cas d’utilisation. On réalise pour cela 3 enregistrements distincts qui exécutent la même exacte séquence de calculs afin que la comparaison soit représentative. On pourra ainsi comparer :
-
l’utilisation des primitifs
-
l’utilisation d’un
record -
l’utilisation d’un
valuerecord
Calculs avec types primitifs (double)
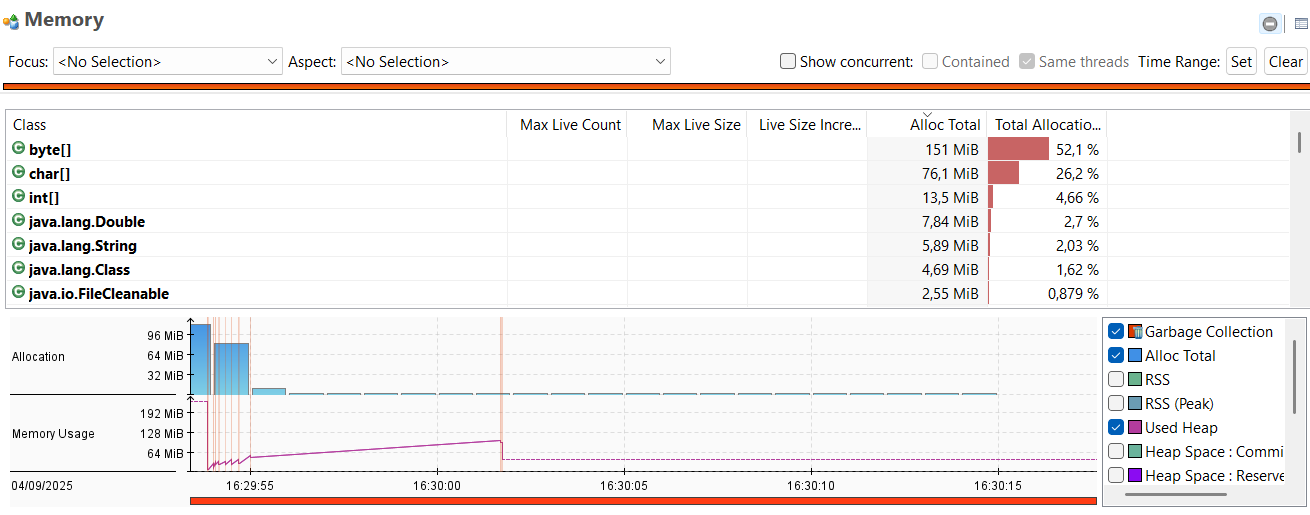
L’utilisation des types primitifs est notre étalon. On constate, sans surprise, qu’il n’y a pas particulièrement d’allocations d’objets, on n’en utilise pas dans l’algorithme, ni d’activité notable du garbage collector. C’est ce que l’on attendait et c’est de cela que découlent les bonnes performances de l’algorithme.
Calculs avec un record
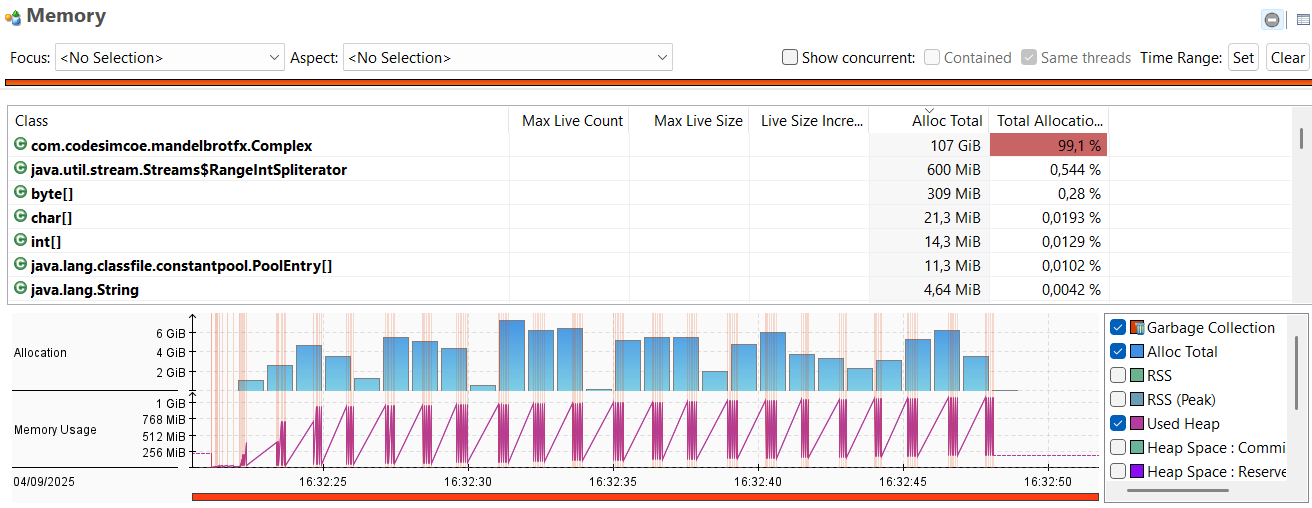
Ici, notre algorithme est extrêmement gourmand (à dessein).
Pour chaque pixel que l’on souhaite calculer, on réalise plusieurs itérations de notre algorithme, qui lui-même alloue plusieurs instances de notre record à chacune de ces itérations.
Les allocations sur le tas (heap) sont nombreuses et on atteint un total de plus de 100Go en même pas 20 secondes d’utilisation.
Le garbage collector est en toute logique soumis à forte contribution.
Calculs avec un value record
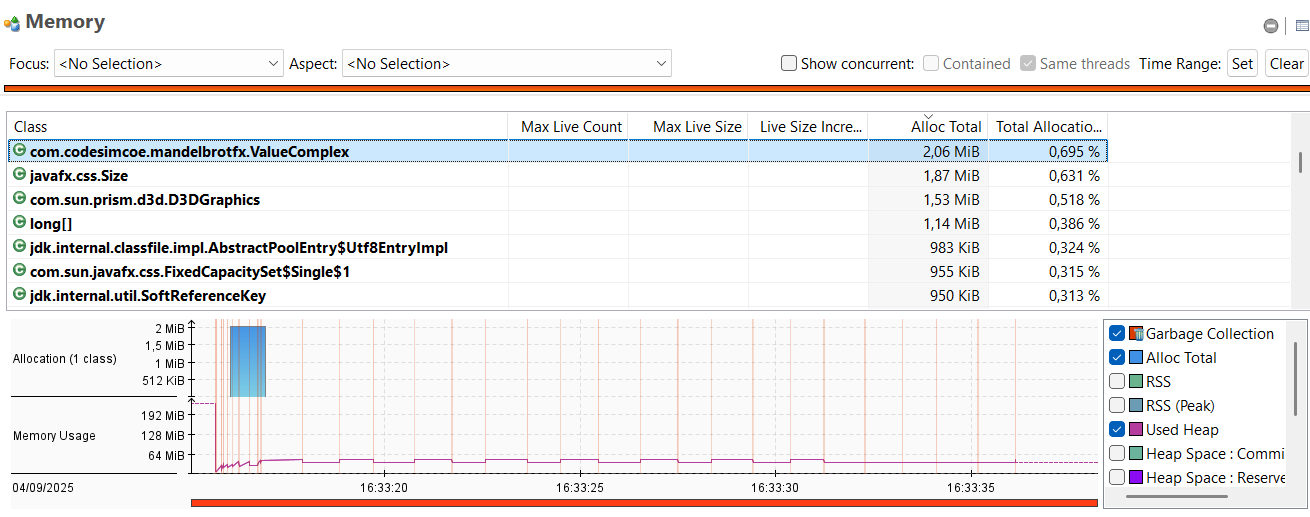
La magie de Valhalla opère : on retrouve un profil semblable au cas d’usage avec les types primitifs. C’est la scalarization qui permet cela : optimisation par laquelle les champs du value type sont décomposés en leurs variables primitives indépendantes pour éviter l’allocation d’un objet sur le tas (heap).
| On note quand même quelques allocations, marginales. Cela est dû au fait que cette optimisation est effectuée au runtime par le compilateur JIT. Il y a donc quelques allocations avant de voir l’optimisation intégrée. |
L’application MandelbrotFx
L’application intégrale est disponible sur github : https://github.com/CodeSimcoe/MandelbrotFx.
La branche valhalla permet de tester les différentes approches à chaud en basculant dynamiquement sur l’algorithme utilisé (primitifs, record ou value record).
La branche main quant à elle se base sur un JDK standard et permet d’explorer l’ensemble de Mandelbrot et sa fascinante structure fractale, ainsi que certaines variantes (Julia, Burning Ship, …).
L’aplatissement (Flattening)
Une optimisation que la JVM peut effectuer avec les value types est l’aplatissement (flattening). À l’exécution, la JVM peut optimiser le stockage des value objects en les représentant sous des formes plus compactes que les objets classiques avec identité : lorsqu’un champ ou un élément de tableau devrait être une référence vers un autre objet, la JVM peut stocker directement les valeurs de cet objet à la place. Dans ce cas, la "référence" n’est plus un pointeur vers une zone mémoire distincte : l’objet est alors dit "aplati" (flattened). Cela donne un stockage plus dense (pas de header), sans indirection.
Reprenons notre type Distance qui encapsule un float :
record Distance(float value) {
public Distance add(Distance other) {
return new Distance(value + other.value);
}
}Considérons un tableau d’objets Distance :
Distance[] array = new Distance[] { ... };Comme Distance est un identity type, le tableau contient pour chaque élément une référence vers une instance de Distance, ou éventuellement null.
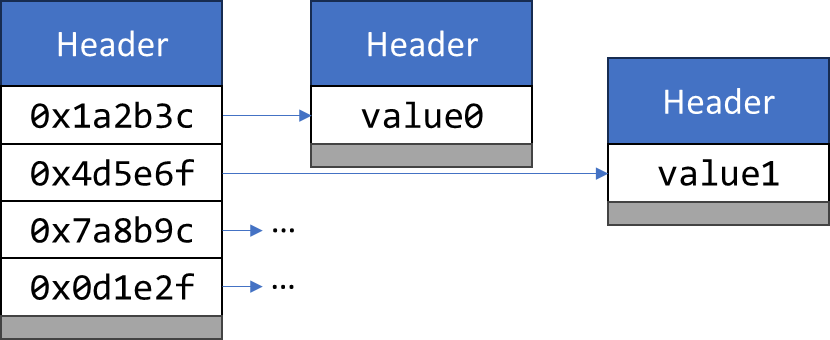
Si l’on utilise plutôt un value record : value record Distance(float value) { … }, l’absence d’identité permettra alors à la JVM "d’aplatir" nos données.
La structure de données en mémoire pourrait revêtir la forme suivante, bien plus dense :

Mais… ce n’est pas aussi simple que cela.
Qu’en est-il de la possible valeur null de notre Distance ?
En plus des 32 bits de notre float, il faudrait un bit supplémentaire pour indiquer si l’instance est null, ou non.
Il est même probable que les contraintes liées au hardware contraignent de devoir utiliser 64 bits au total, soit donc 32 bits rien que pour le bit de "nullité".
Alors, la structure de données serait plus proche d’une telle représentation :

Si l’on impose, pour un cas d’usage donné, que l’instance du value type n’est jamais nulle, alors on peut s’affranchir du bit supplémentaire et encoder directement les valeurs.
C’est ce que proposent de traiter les JEP draft JDK-8303099: Null-Restricted and Nullable Types et JDK-8316779: Null-Restricted Value Class Types en deux temps.
Le langage se verrait alors enrichi d’une nouvelle possibilité : la capacité de pouvoir exprimer si les valeurs d’un type acceptent la valeur null, ou pas.
La syntaxe pressentie (non définitive) est l’utilisation du point d’exclamation ! après le type.
Il serait donc possible, à terme, de définir notre tableau d’objets Distance de la manière suivante :
Distance![] distances = {
new Distance(100f),
new Distance(200f)
};Un tel tableau pourrait ainsi être stocké de la même manière que : float[], chaque instance de Distance n’étant représentée que par le float qu’elle encapsule, sans information de nullité.
Une autre contrainte arrive aussi rapidement, celle de l’intégrité de nos données. Dès lors que la taille du value object à stocker dépasse celle de la capacité du processeur — supposons 64 bits — il n’y a plus d’atomicité garantie : il est alors possible d’observer une instance incohérente. Prenons l’exemple suivant :
var Complex c1 = new Complex(1, 2);
var Complex c2 = new Complex(3, 4);Dans un cas de concurrence en écriture, il serait possible de créer un Complex ayant pour valeurs re = 1, im = 4 par exemple, ce qui ne correspond à aucune de nos deux instances, mais à un mix de certaines de leurs valeurs.
Dans une philosophie d’une JVM qui assure une intégrité par défaut, cela n’est pas souhaitable, et limite ainsi la façon dont les objets peuvent être aplatis.
Si l’on considère la classe LocalDateTime (un type candidat pour devenir value type), son contenu excède 64 bits.
On pourrait néanmoins le stocker de manière partiellement optimisée en conservant un pointeur vers l’instance, mais dont le stockage serait aplati de la manière suivante :
-
64 bits pour sa partie
LocalDate -
64 bits pour sa partie
LocalTime
LocalDate +-------------------------------------------------------------+ | year month day | | YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY MMMMMMMM DDDDDDDD ________ | | int byte byte | +-------------------------------------------------------------+ LocalTime +-------------------------------------------------------------+ | HHHHHHHH MMMMMMMM SSSSSSSS NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN | | hour minute second nano | | byte byte byte int | +-------------------------------------------------------------+
Il serait néanmoins possible de renoncer à l’atomicité, de manière explicite uniquement.
La JEP propose d’activer ce choix via l’implémentation d’une interface LooselyConsistentValue : c’est une proposition à l’état d’ébauche (cela pourrait être une annotation, ou un nouveau mot clé par exemple).
Auquel cas, le flattening pourrait être réalisé au-delà de la limite des 64bits.
Mais la philosophie souhaitée est claire : intégrité par défaut.
La route est encore longue
Ces quelques exemples illustrent certaines des futures fonctionnalités apportées par le projet Valhalla.
Mais les étages de la fusée Valhalla sont nombreux : la JEP 402: Enhanced Primitive Boxing prévoit de rapprocher les types primitifs un peu plus des types objets : un int serait presque un Integer!.
On pourrait accéder aux champs d’un int i comme i.SIZE ou appeler une méthode telle que i.doubleValue()…
Enfin, Valhalla devra s’attaquer au type erasure : les types génériques étant effacés au runtime, il n’est pas possible d’optimiser les conteneurs génériques comme Optional<T> ou les collections telles que java.util.List<T>.
Il faudra une évolution qui permette de conserver l’information nécessaire à l’optimisation.
Toutes ces fonctionnalités devront encore longuement maturer, mais la JEP 401: Value Classes and Objects n’a jamais été aussi proche d’atterrir en preview dans une prochaine version du JDK !
Sommaire :